Последние несколько лет стали свидетелями роста популярности генеративного ИИ и больших языковых моделей (LLM) как части широкой революции в области ИИ. Поскольку приложения на основе LLM внедряются в компании, существует необходимость определить экономическую эффективность различных решений для обслуживания ИИ. Стоимость развертывания приложения LLM зависит от того, сколько запросов оно может обрабатывать в секунду, оставаясь при этом отзывчивым к конечным пользователям и поддерживая приемлемый уровень точности ответов. Этот пост сосредоточен конкретно на измерении пропускной способности LLM и латентности в рамках оценки затрат на приложения LLM.
NVIDIA предоставляет разработчикам платформенные инновации, охватывающие чипы, системы и программное обеспечение. Стек программного обеспечения для вывода NVIDIA включает в себя NVIDIA Dynamo, NVIDIA TensorRT-LLM и NVIDIA NIM микросервисы. Чтобы поддержать разработчиков в оценке производительности вывода, NVIDIA также предлагает GenAI-Perf, инструмент для оценки генеративного ИИ с открытым исходным кодом. Узнайте больше о использовании GenAI-Perf для оценки.
Оценка производительности LLM может быть выполнена с использованием различных инструментов. Эти клиентские инструменты предлагают конкретные метрики для приложений на базе LLM, но отличаются тем, как они определяют, измеряют и рассчитывают различные метрики. Это может быть запутанным и затруднять сравнение результатов одного инструмента с результатами другого.
В этом посте мы проясняем общие метрики и тонкие различия в том, как популярные инструменты оценки определяют и измеряют эти метрики. Мы также обсудим важные параметры для оценки.
Нагрузочное тестирование и оценка производительности
Нагрузочное тестирование и оценка производительности — это два различных подхода к оценке развертывания LLM. Нагрузочное тестирование сосредоточено на моделировании большого количества конкурирующих запросов к модели, чтобы оценить ее способность справляться с реальным трафиком в большом масштабе. Этот тип тестирования помогает выявить проблемы, связанные с емкостью сервера, методами автоматического масштабирования, сетевой задержкой и использованием ресурсов.
В отличие от этого, оценка производительности, как показывает инструмент NVIDIA GenAI-Perf, касается измерения фактической производительности самой модели, такой как ее пропускная способность, латентность и метрики на уровне токенов. Этот тип тестирования помогает выявить проблемы, связанные с эффективностью модели, оптимизацией и конфигурацией.
Хотя нагрузочное тестирование необходимо для обеспечения того, чтобы модель могла обрабатывать большой объем запросов, оценка производительности имеет решающее значение для понимания способности модели эффективно обрабатывать запросы. Сочетая оба подхода, разработчики могут получить всестороннее понимание возможностей развертывания своего LLM и выявить области для улучшения.
Как работает вывод LLM
Перед тем как изучать метрики оценки, важно понять, как работает вывод LLM, и познакомиться с сопутствующей терминологией. Приложение LLM выдает результаты через стадии вывода. Для конкретного приложения LLM эти стадии включают:
- Запрос: Пользователь предоставляет вопрос
- Очередь: Запрос присоединяется к очереди на обработку
- Предварительная обработка: Модель LLM обрабатывает запрос
- Генерация: Модель LLM выдает ответ, один токен за раз
Токен ИИ token — это концепция, специфичная для LLM и имеющая центральное значение для метрик производительности вывода LLM. Это единица, или наименьшая языковая сущность, которую LLM используют для разбора и обработки естественного языка. Собрание всех токенов известно как словарь. Каждая LLM имеет собственный токенизатор, который изучается на основе данных для эффективного представления входного текста. В качестве приближения для многих популярных LLM каждый токен составляет ~0.75 английских слов.
Длина последовательности — это длина последовательности данных. Длина входной последовательности (ISL) — это сколько токенов получает LLM. Она включает в себя запрос пользователя, любые системные подсказки (инструкции для модели, например), предыдущее чат-историю, цепочку размышлений (CoT) и документы из потока, дополненного извлечением (RAG). Длина выходной последовательности (OSL) — это сколько токенов генерирует LLM. Длина контекста — это сколько токенов использует LLM на каждом шаге генерации, включая как входные, так и выходные токены, сгенерированные на данный момент. Каждая LLM имеет максимальную длину контекста, которая может быть выделена как для входных, так и для выходных токенов. Для более глубокого изучения вывода LLM см. Об mastering LLM Techniques: Оптимизация вывода.
Стриминг — это опция, которая позволяет частичным выходам LLM быть переданными пользователям в виде кусочков токенов, сгенерированных поэтапно. Это важно для приложений чат-ботов, где желателен быстрый ответ. В то время как пользователь усваивает частичное содержимое, следующий кусок результата arrives in the background. В отличие от них, в режиме несетевый, полный ответ возвращается целиком.
Метрики вывода LLM
Этот раздел объясняет некоторые из общих метрик, используемых в отрасли, включая время до первого токена и задержку между токенами, как показано на Рисунке 1. Хотя они кажутся простыми, есть некоторые незначительные, но значительные различия между различными инструментами оценки.
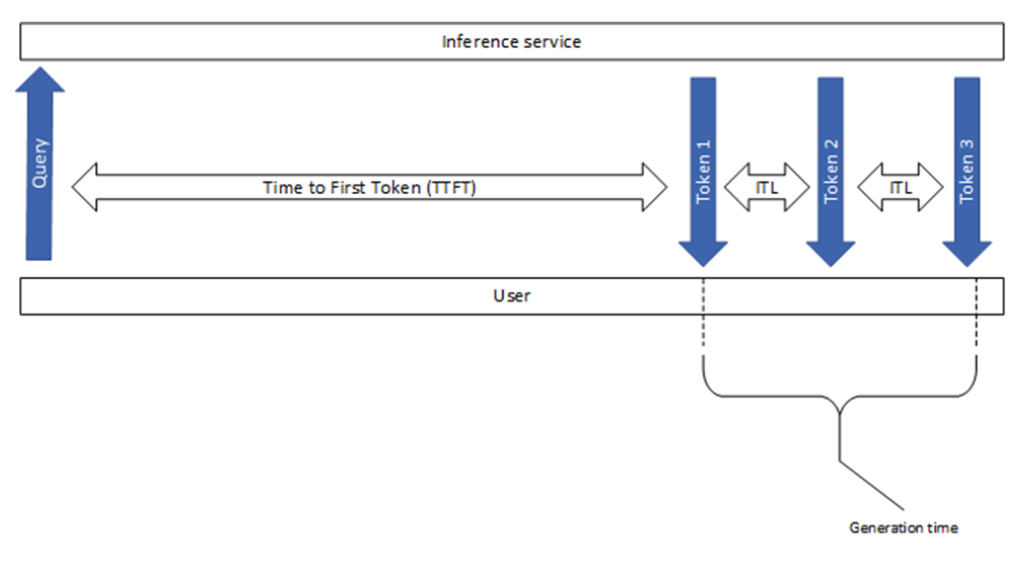
Время до первого токена
Время до первого токена (TTFT) — это время, необходимое для обработки запроса и генерации первого токена (Рисунок 2). Другими словами, это измеряет, сколько времени пользователь должен ждать, прежде чем увидит вывод модели.
Обратите внимание, что как инструменты GenAI-Perf, так и LLMPerf не учитывают начальные ответы, которые не содержат информации или содержат пустую строку (токен отсутствует). Это потому, что измерение TTFT не имеет смысла, когда первый ответ не содержит токенов.
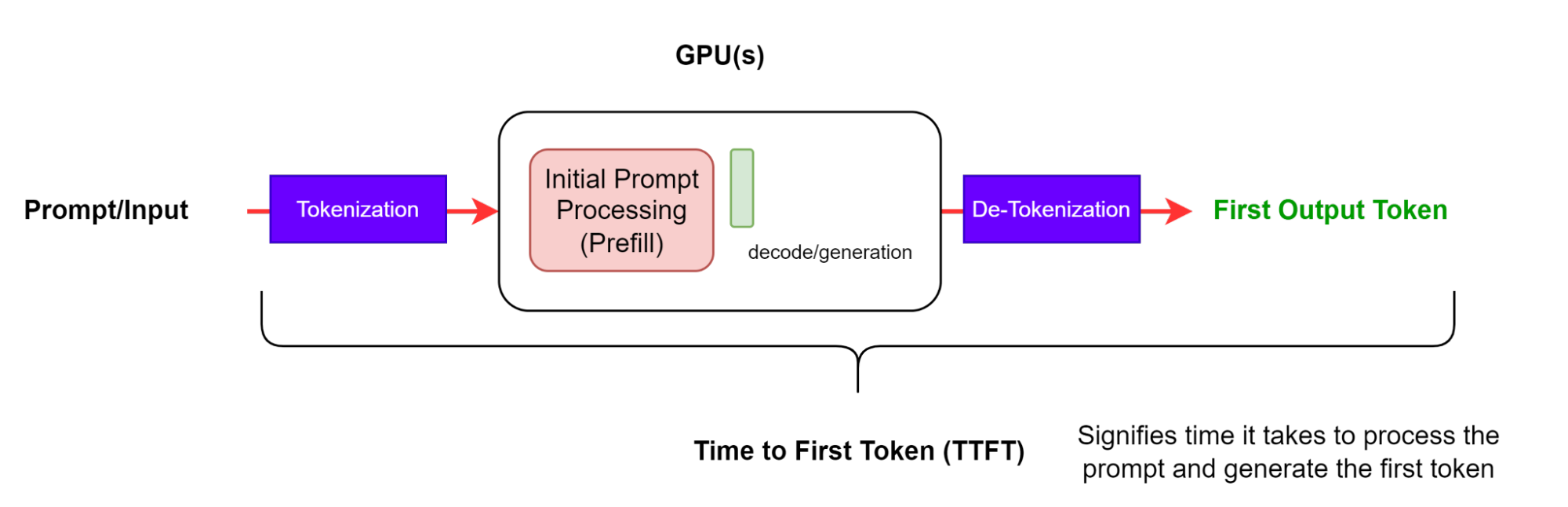
TTFT обычно включает время ожидания запросов, время предварительной обработки и сетевую задержку. Чем длиннее запрос, тем больше TTFT. Это связано с тем, что механизм внимания требует всю входную последовательность для вычисления и создания так называемого ключевого-значения (KV) кеша, с которого начинается итеративный цикл генерации. Кроме того, в производственном приложении может быть несколько запросов в процессе обработки, поэтому фаза предварительной обработки одного запроса может пересекаться с фазой генерации другого запроса.
Задержка по запросам от начала до конца
Задержка по запросам от начала до конца (e2e_latency) указывает на время, которое проходит от момента отправки запроса до получения полного ответа, включая время на очереди и пакетирование и сетевые задержки (Рисунок 3). Обратите внимание, что в режиме стриминга шаг детокенизации может выполняться несколько раз, когда частичные результаты возвращаются пользователю.

Для отдельного запроса задержка по запросу от начала до конца — это временной интервал между моментом отправки запроса и получением последнего токена:

Обратите внимание, что generation_time — это продолжительность от момента получения первого токена до момента получения последнего токена (Рисунок 1). Кроме того, GenAI-Perf исключает последний (завершенный) сигнал или пустой ответ, поэтому они не включаются в e2e_latency.
Задержка между токенами
Задержка между токенами (ITL) — это среднее время между генерацией последовательных токенов в последовательности. Она также известна как время на выходной токен (TPOT).
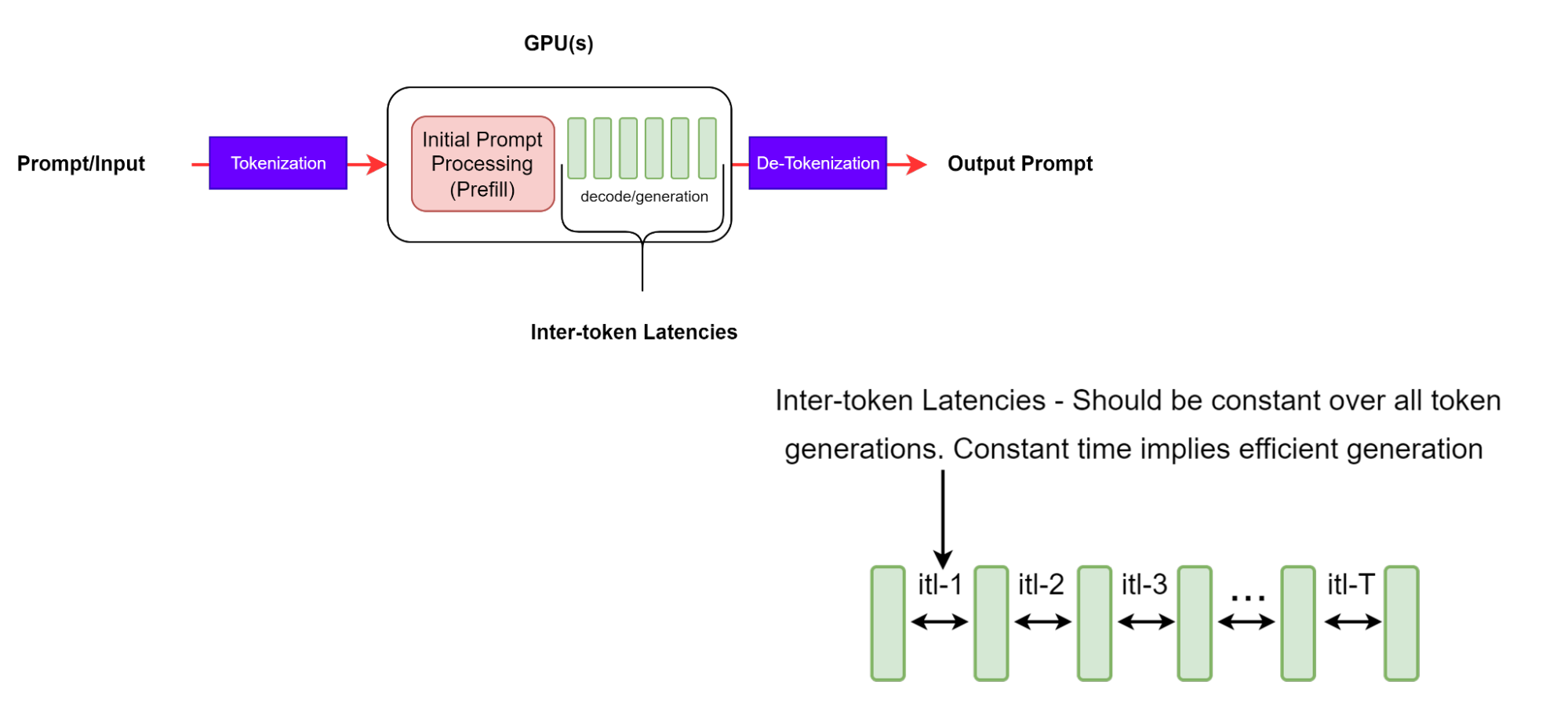
Хотя это кажется простой концепцией, существуют некоторые тонкие различия в том, как метрика собирается различными инструментами оценки. Например, GenAI-Perf не включает TTFT в среднее значение (в отличие от LLMPerf, который включает TTFT).
GenAI-Perf определяет ITL по следующему уравнению:

Уравнение, используемое для этой метрики, не включает первый токен (поэтому вычитание 1 в знаменателе). Это сделано, чтобы ITL было характеристикой только части распознавания во время обработки запроса.
Стоит отметить, что при более длинных выходных последовательностях кеш KV увеличивается, поэтому стоимость памяти также растет. Стоимость вычисления внимания также растет: для каждого нового токена эта стоимость линейна по длине входной и выходной последовательностей, созданных до этого момента. Однако это вычисление обычно не является вычислительно ограниченным. Последовательные ITL свидетельствуют об эффективном управлении памятью и лучшей пропускной способности памяти, а также эффективном вычислении внимания.
Токены в секунду
Токены в секунду (TPS) для системы представляют собой общее количество токенов в секунду, с учетом всех запросов, происходящих одновременно. Когда количество запросов увеличивается, общее количество TPS для системы будет расти, пока не достигнет точки насыщения для всех доступных ресурсов вычислений GPU, после чего оно, возможно, уменьшится.
Для примера, показанного на Рисунке 5, предположим временную линию всего бенчмарка с n общими запросами. События определяются следующим образом:
- Li: Задержка от начала до конца i-го запроса
- T_start: Начало бенчмарка
- Tx: Временная метка первого запроса
- Ty: Временная метка последнего ответа последнего запроса
- T_end: Конец бенчмарка

GenAI-Perf определяет TPS как общее количество выходных токенов, деленное на задержку от начала до конца между первым запросом и последним ответом последнего запроса:

LLMPerf определяет TPS как общее количество выходных токенов, деленное на продолжительность всего бенчмарка:

Таким образом, LLM-perf также включает в себя следующие накладные расходы в метрику:
- Генерация входного запроса
- Подготовка запроса
- Хранение ответов.
По нашим наблюдениям, эти накладные расходы в сценарии единственной конкурентности могут иногда составлять 33% от всей продолжительности бенчмарка.
Обратите внимание, что расчёт TPS выполняется в пакетном режиме и не является метрикой live. Кроме того, GenAI-Perf использует технику скользящего окна для получения стабильных измерений. Это означает, что указанные измерения будут из репрезентативного подмножества полностью завершенных запросов, что означает, что «разогревающие» и «охлаждающие» запросы не включаются при расчете метрик.
TPS на пользователя представляет собой пропускную способность с точки зрения одного пользователя и определяется как:

Это определение относится к запросу каждого пользователя, который асимптотически стремится к 1/ITL по мере увеличения длины выходной последовательности. Обратите внимание, что по мере увеличения числа параллельных запросов в системе общее TPS для всей системы будет увеличиваться, тогда как TPS на пользователя уменьшается по мере увеличения задержки.
Запросы в секунду
Запросы в секунду (RPS) — это среднее количество запросов, которые могут быть успешно выполнены системой за 1 секунду. Он рассчитывается следующим образом:

Параметры оценки и лучшие практики
Этот раздел представляет некоторые важные параметры тестирования и их диапазон, которые обеспечивают значимую оценку и обеспечение качества.
Сценарии использования приложений и их влияние на производительность LLM
Специфические сценарии использования приложения будут влиять на длины последовательностей (ISL и OSL), которые, в свою очередь, повлияют на то, как быстро система обрабатывает ввод для формирования кеша KV и генерации выходных токенов. Более длинный ISL увеличит требования к памяти для этапа предварительной обработки и, таким образом, увеличит TTFT. Более длинный OSL увеличит требования к памяти (как пропускная способность, так и емкость) для этапа генерации и, таким образом, увеличит ITL. Важно понимать распределение входов и выходов в развертывании вашего LLM, чтобы оптимизировать использование оборудования.
Распространенные сценарии использования и вероятные пары ISL/OSL включают:
- Перевод: Включает перевод между языками и кодом и характеризуется аналогичными ISL и OSL, примерно по 500~2000 токенов каждый.
- Генерация: Включает генерацию кода, рассказа и содержания электронной почты, а также общего содержания через поиск. Это характеризуется OSL порядка O(1,000) токенов, гораздо длиннее ISL порядка O(100) токенов.
- Суммирование: Включает извлечение, подсказки цепочки размышлений и многосерийные беседы. Это характеризуется ISL порядка O(1000) токенов, гораздо длиннее OSL порядка O(100) токенов.
- Размышление: Недавние модели размышления генерируют большое количество выходных токенов в явной цепочке размышлений, самоанализа и верификации, чтобы решить сложные проблемы, такие как программирование, математика или головоломки. Это характеризуется коротким ISL порядка O(100) токенов и большим OSL порядка O(1000-10000) токенов.
Параметры управления нагрузкой
Параметры управления нагрузкой, указанные в этом разделе, используются для создания нагрузок на системы LLM.
Конкуренция N — это количество конкурирующих пользователей, каждый из которых имеет один активный запрос, или, эквивалентно, количество запросов, одновременно обслуживаемых службой LLM. Как только запрос каждого пользователя получает полный ответ, отправляется другой запрос, чтобы обеспечить наличие именно N запросов в системе. Конкуренция чаще всего используется для описания и управления нагрузкой, которая предъявляется к системе вывода.
Обратите внимание, что LLMPerf отправляет запросы партиями из N запросов, но существует период откачки, когда он ждет, пока все запросы завершатся, прежде чем отправить следующую партию. Таким образом, к концу партии количество конкурирующих запросов постепенно уменьшается до 0. Это отличается от GenAI-Perf, который всегда обеспечивает N активных запросов на протяжении всего периода оценки.
Параметр максимальный размер партии определяет максимальное количество запросов, которые движок вывода может обрабатывать одновременно, где партия — это группа одновременно обрабатываемых запросов движком вывода. Это может быть подмножество конкурирующих запросов.
Если конкуренция превышает максимальный размер партии, умноженный на количество активных реплик, некоторые запросы будут вынуждены ожидать в очереди для дальнейшей обработки. В этом случае вы можете заметить увеличение значения TTFT из-за эффекта очереди ожидания, пока не освободится место.
Скорость запроса — это еще один параметр, который можно использовать для управления нагрузкой, определяя скорость, с которой отправляются новые запросы. Использование постоянной (или статической) скорости запросов r означает, что 1 запрос отправляется каждые 1/r секунд, в то время как использование пуассоновской (или экспоненциальной) скорости запроса определяет среднее время между поступлениями.
GenAI-Perf поддерживает как конкуренцию, так и скорость запросов. Однако мы рекомендуем использовать конкуренцию. Точно так же, как и в случае скорости запросов, количество незавершенных запросов может расти неограниченно, если запрос в секунду превышает пропускную способность системы.
При указании конкуренции для тестирования полезно проходить по диапазону значений от минимального значения 1 до максимального значения, которое не намного больше максимального размера партии. Это связано с тем, что при увеличении конкуренции выше максимального размера партии движка некоторые запросы будут вынуждены ожидать в очереди. Поэтому, как правило, пропускная способность системы насыщается вокруг максимального размера партии, в то время как задержка будет продолжать устойчиво увеличиваться.
Другие параметры
Кроме того, есть соответствующие параметры обслуживания LLM, которые могут влиять на производительность вывода, а также на точность оценки.
У большинства LLM есть специальный токен конца последовательности (EOS), который обозначает конец генерации. Он указывает, что LLM сгенерировала полный ответ и должна остановиться. При общем использовании LLM вывод должен уважать этот сигнал и прекращать генерацию дальнейших токенов. Параметр ignore_eos обычно указывает, должен ли фреймворк вывода LLM игнорировать токен EOS и продолжать генерировать токены до достижения лимита max_tokens. Для целей оценки этот параметр должен быть установлен в True, чтобы достичь предполагаемой длины вывода и получить последовательные измерения.
Различные параметры выборки (например, жадный выбор, top_p, top_k и температура) могут повлиять на скорость генерации LLM. Жадный выбор, например, может быть реализован просто путем выбора токена с наивысшим логитом. Нет необходимости нормализовывать и сортировать распределение вероятностей по токенам, что экономит вычисления. Какой бы метод выборки вы ни выбрали, разумно придерживаться одного и того же сценария оценки. Для более подробного объяснения различных методов выборки см. Как генерировать текст: Используя различные методы декодирования для генерации текста с трансформерами.
Начните работу
Оценка производительности LLM — это важный шаг для обеспечения как высокой производительности, так и экономически эффективного обслуживания LLM в больших масштабах. В этом посте обсуждались наиболее важные метрики и параметры при оценке вывода LLM. Чтобы узнать больше, ознакомьтесь с этими ресурсами:
- Искусственный интеллект: балансировка стоимости, задержки и производительности
- Как развернуть NVIDIA NIM за 5 минут
- Простой гид по развертыванию генеративного ИИ с NVIDIA NIM
Изучите платформу NVIDIA AI Inference и посмотрите последние данные о производительности вывода ИИ. Оптимизации из библиотек TensorRT, TensorRT-LLM и TensorRT Model Optimizer объединены и доступны через развертывания, готовые к производству, с использованием микросервисов NVIDIA NIM.