Федеративное обучение (FL)
Федеративное обучение (FL) стало многообещающим подходом к обучению моделей машинного обучения на распределенных источниках данных, сохраняя при этом конфиденциальность данных. Однако FL сталкивается с серьезными проблемами, связанными с затратами на связь и ограничениями локальных ресурсов при балансировке требований к модели и возможностями связи.
В особенности в современную эпоху больших языковых моделей (LLM) FL сталкивается с вычислительными трудностями при развертывании LLM с миллиардами параметров. Огромные размеры этих моделей усугубляют как проблемы связи, так и ограничения по памяти. Передача полных обновлений модели за один раз может оказаться неприемлемой из-за ограничений пропускной способности, а локальные ограничения по памяти могут усложнить обработку крупных моделей для связи. Решение этих проблем требует инновационных стратегий.
NVIDIA FLARE, независимый от доменов, открытый и расширяемый SDK для федеративного обучения, улучшил практический опыт в области федеративного обучения, представив надежные возможности связи, поддержку нескольких одновременных обучающих заданий и устойчивость к потенциальным сбоям заданий из-за сетевых условий.
Версия NVFlare 2.4.0 представила потоковый API для облегчения передачи объектов, превышающих лимит по размеру в 2 ГБ, установленный gRPC. Он добавил новый потоковый слой, предназначенный для надежной передачи крупных сообщений данных.
С помощью потокового API вы больше не ограничены пределом размера в 2 ГБ gRPC. Однако, с тем, как современные модели становятся все больше, существуют две проблемы, которые становятся узким местом в процессе FL с LLM:
- Размер передаваемого сообщения при стандартной точности fp32
- Локальное распределение памяти для хранения объекта во время передачи
Чтобы обеспечить более эффективный и надежный федеративный процесс, в NVFlare 2.6.0 мы представили две ключевые технологии, которые способствуют уменьшению размера сообщения и эффективной передаче памяти:
- Квантование сообщений: Квантование и деквантование реализованы с помощью фильтров NVFlare и добавлены к федеративным схемам, что снижает размер сообщения во время передачи.
- Потоковая передача контейнеров и файлов: Потоковые возможности реализованы на основе ObjectStreamer. Мы поддерживаем два типа объектов: контейнеры и файлы, и разработали класс ObjectRetriever для более легкой интеграции с существующим кодом.
Квантование сообщений: уменьшение затрат на связь
Одна из основных узких мест в FL — это обмен обновлениями модели среди удаленных участников и серверов. Размер этих сообщений может быть чрезмерно большим, что приводит к увеличению задержек и потреблению пропускной способности. Учитывая, что современные LLM обучаются с уменьшенной точностью, стандартная точность сообщения fp32 в формате NumPy может даже искусственно увеличивать размер сообщения.
В этом случае мы реализовали две функции: прямую передачу тензоров и квантование сообщений, предлагая эффективное решение сообщений, позволяя использовать родную точность обучения, а также снижая точность передаваемых обновлений и уменьшая размер сообщения.
Рисунок 1 показывает реализацию квантования и деквантования с помощью этого механизма фильтров. Квантование осуществляется для исходящих весов модели перед передачей, а деквантование восстанавливает изначальную точность после получения сообщения на другой стороне.
Существует два преимущества такой реализации:
- Не требуется изменение кода со стороны пользователя. Один и тот же скрипт обучения может использоваться как с квантованием сообщений, так и без него с простой настройкой конфигурации.
- Оба процесса — обучение и агрегирование — осуществляются с оригинальной точностью, а не квантованными данными, что минимизирует потенциальное влияние квантования сообщения на процесс обучения.
Мы использовали прямое обрезание и преобразование для преобразования fp32 в fp16 и использовали bitsandbytes для выполнения квантования 8 и 4 бита. С этими новыми функциями мы поддерживаем как массивы NumPy (предыдущий стандарт), так и тензоры PyTorch непосредственно для обучения LLM.
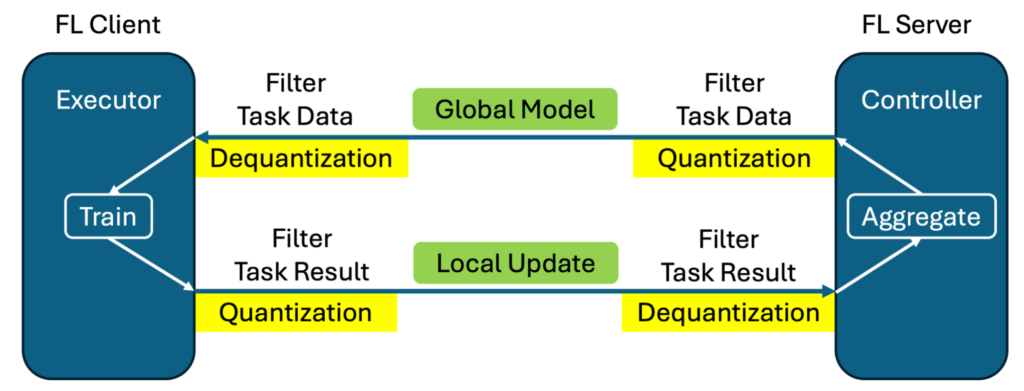
Таблица 1 показывает размер сообщения в МБ для LLM с 1B параметров при различных точностях. Для получения дополнительной информации о выравнивании кривых потерь в обучении, см. пример NVIDIA/NVFlare на HuggingFace SFT/PEFT API.
| Точность | Размер модели (МБ) | Размер метаданных квантования (МБ) | Размер fp32 | Процент |
| 32-бит (fp32) | 5716.26 | 0.00 | 100.00 % | |
| 16-бит (fp16, bf16) | 2858.13 | 0.00 | 50.00 % | |
| 8-бит | 1429.06 | 1.54 | 25.03 % | |
| 4-бит (fp4, nf4) | 714.53 | 89.33 | 14.06 % |
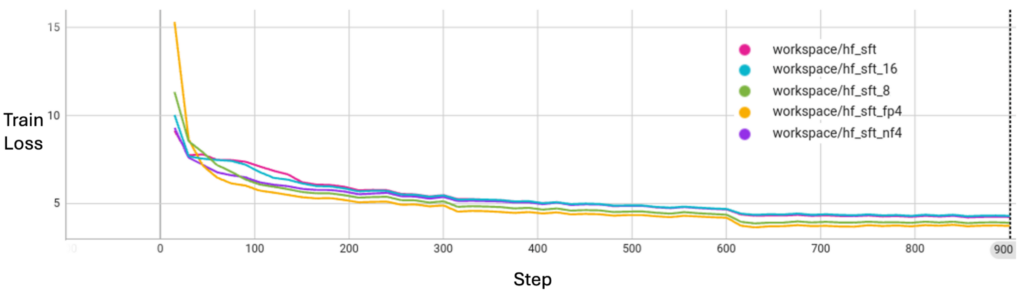
Применяя техники квантования сообщений, FL может достичь значительной экономии пропускной способности, а также для обучения LLM с помощью Supervised Fine-Tuning (SFT) в наших экспериментах.
Как показано на рисунке 2, квантование сообщений не жертвует качеством сходимости модели с точки зрения потерь при обучении.
Потоковая функциональность: уменьшение использования локальной памяти
Еще одной критической проблемой в FL является перерасход памяти на отправку и получение сообщений.
При стандартных настройках, чтобы отправить модель, вам нужна дополнительная память, чтобы подготовить и получить кусочки модели, что требует удвоения использования локальной памяти. Дополниельная память должна быть выделена для хранения всего сообщения, чтобы перенастроить объект, хотя сама передача выполняется потоками по 1М кусочков.
Такой перерасход памяти может быть приемлемым при приличных системных возможностях и умеренном размере модели, но когда вы рассматриваете модель с 70B или более параметрами, она может быстро исчерпать доступную системную память. Модель 70B может иметь размер 140 ГБ. Чтобы загрузить и отправить ее, вам потребуется 140 + 140 = 280 ГБ памяти.
Несмотря на то, что весь параметрический словарь LLM может быть огромен, при разбивке на отдельные слои и элементы максимальный размер каждого слоя значительно меньше, обычно около 1 ГБ. Улучшенная потоковая функциональность решает проблему использования памяти с помощью двух новых функций:
- Потоковая передача объектов-контейнеров: Обработка и передача модели по частям, а не требуется, чтобы весь объект хранился в памяти одновременно. Потоковая передача контейнеров сериализует один элемент объекта (например, словарь, содержащий веса модели) за раз. Для приведенного ранее примера модели размером 140 ГБ с максимальным размером элемента 1 ГБ, в отличие от 280 ГБ, если отправить его целиком, ContainerStreamer требует только 140 + 1 = 141 ГБ памяти для загрузки и отправки.
- Потоковая передача файлов: Потоковая передача файла, а не структурированного контейнера объекта. Потоковая передача файлов считывает файл по частям и использует только ту память, которая необходима для удержания одного кусочка данных. Дополнительная память, необходимая FileStreamer, не зависит от размера модели или максимального размера элемента и относится только к настройкам файлового ввода-вывода, что может минимизировать использование памяти при передаче и обеспечивать неограниченную потоковую передачу. В этом случае загрузка модели не требуется, поэтому вы можете дополнительно сэкономить на использовании памяти, если это необходимо.
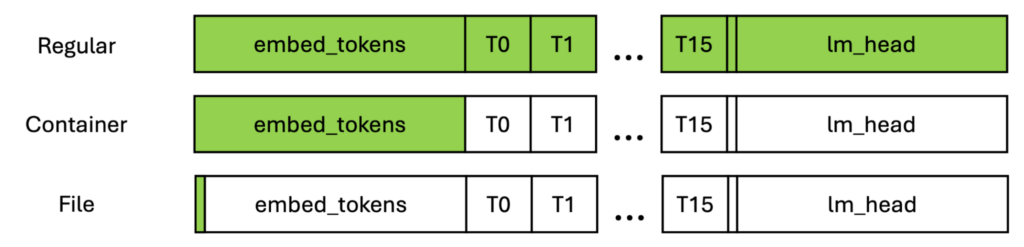
На рисунке 3 зеленые прямоугольники показывают максимальную локальную память, которая должна быть выделена для передачи сообщений. Как видно, обычная передача требует выделения памяти для всей модели, поэтому это может быть неограниченно, поскольку модели становятся все больше.
Для контейнера объекта память равна размеру самого большого слоя, который часто ограничивается первыми и последними слоями. Для файловое требование по памяти не зависит от структуры модели и может быть настроено для любого файла.
Применяя потоковую передачу в FL, вы можете добиться эффективности использования памяти, разбивая обновления на более мелкие кусочки и обрабатывая их последовательно. Потоковая передача уменьшает пиковое использование памяти, делая FL осуществимым, оптимизируя вычислительные ресурсы.
С этим решением вы даже можете добиться обработки в реальном времени, позволяя устройствам передавать частичные обновления, продолжая вычисления, улучшая отзывчивость и уменьшая простои. На стороне приемника стратегии обновления также могут выигрывать от адаптивной передачи, при которой обновления могут отправляться с переменной степенью детализации в зависимости от сетевых условий и доступности клиента.
Таблица 2 показывает сравнение памяти с локальной симуляцией одновременной отправки модели 1B. Мы зафиксировали «отпечаток» системной памяти и сравнили пиковое использование памяти по трем настройкам: обычной, потоковой передачи контейнеров и потоковой передачи файлов.
Вы можете увидеть, что использование памяти значительно снижено при использовании потоковой передачи, особенно для потоковой передачи файлов. Однако, потоковая передача файлов может занять больше времени для завершения работы из-за эффективности ввода-вывода файлов.
| Настройка | Пиковое использование памяти (МБ) | Время завершения работы (сек) |
| Обычная передача | 42,427 | 47 |
| Потоковая передача контейнеров | 23,265 | 50 |
| Потоковая передача файлов | 19,176 | 170 |
Улучшения потоковой передачи еще не интегрированы в высокоуровневые API или существующие алгоритмы контроля и выполнения FL. Тем не менее, вы можете создать собственные контроллеры или исполнители, следуя этому примеру потоковой передачи, чтобы использовать эту функцию.
Резюме
В этом посте мы продемонстрировали, как облегчить коммуникационные узкие места и ограничения по памяти, интегрируя квантование сообщений и потоковую функциональность в FL фреймы. С улучшенными возможностями мы делаем федеративное обучение более эффективным и масштабируемым. По мере того как эти технологии продолжают развиваться, они будут играть важную роль в обеспечении реального развертывания FL в разных условиях.
Для получения дополнительной информации смотрите следующие ресурсы:
- /Учебные пособия NVFlare на GitHub
- /Примеры квантования NVIDIA/NVFlare на GitHub
- /Примеры потоковой передачи NVIDIA/NVFlare на GitHub
- Портал разработчиков NVIDIA FLARE
- Федеративное Обучение в Медицинской Визуализации: Повышение Конфиденциальности Данных и Продвижение Здравоохранения Сессия GTC 2025
Чтобы связаться с командой NVIDIA FLARE, пишите на [email protected].
Теги
Научные исследования данных | Граничные вычисления | Генеративный ИИ | Общее | FLARE | Дополнительные технические знания | Лучшие практики | Федеративное Обучение | Интернет/Связь
Об авторах

Об Зиюэ Сю
Зиюэ Сю — старший научный сотрудник в NVIDIA. Его исследовательские интересы включают анализ медицинских изображений, компьютерное зрение и федеративное обучение. На протяжении многих лет он работал над совместной разработкой ИИ вместе с другими исследователями и клиницистами. Зиюэ получил степень бакалавра в Цинхуа в 2006 году, а также степень магистра и доктора в Университете Айовы в 2009 и 2012 годах соответственно. Он является старшим членом IEEE, председателем секции на крупных конференциях и ассистентом редактора для нескольких журналов, включая IEEE Transactions of Medical Imaging (TMI) и International Journal of Computer Vision (IJCV).Посмотреть все записи Зиюэ Сю

Об Жихун Чжан
Жихун Чжан — инженер-программист, работающий над рамками федеративного обучения в NVIDIA. Среди прочего, он разработал F3 (Flare Federation Framework) и FOBS (Flare Object Serialization). У него обширный опыт в распределенных системах и обработке больших данных. Прежде чем присоединиться к NVIDIA, он работал в PIXIA и AOL в области соединения и обработки спутниковых изображений.Посмотреть все записи Жихун Чжан

Об Яне Ченг
Ян Ченг возглавляет инженерную команду, которая тесно сотрудничает с исследователями DLMED, чтобы разработать и реализовать SDK Clara Train. У него многолетний опыт создания качественных программных систем для промышленности. Перед тем как присоединиться к NVIDIA, он работал главным архитектором в AOL и занимался ИТ-консалтингом для федерального правительства.Посмотреть все записи Ян Ченг
