Эффективное масштабирование Parquet Reader на GPU с использованием Polars
10 апреля 2025 года
Авторы: Прем Сагар Гали и Брендон Миллер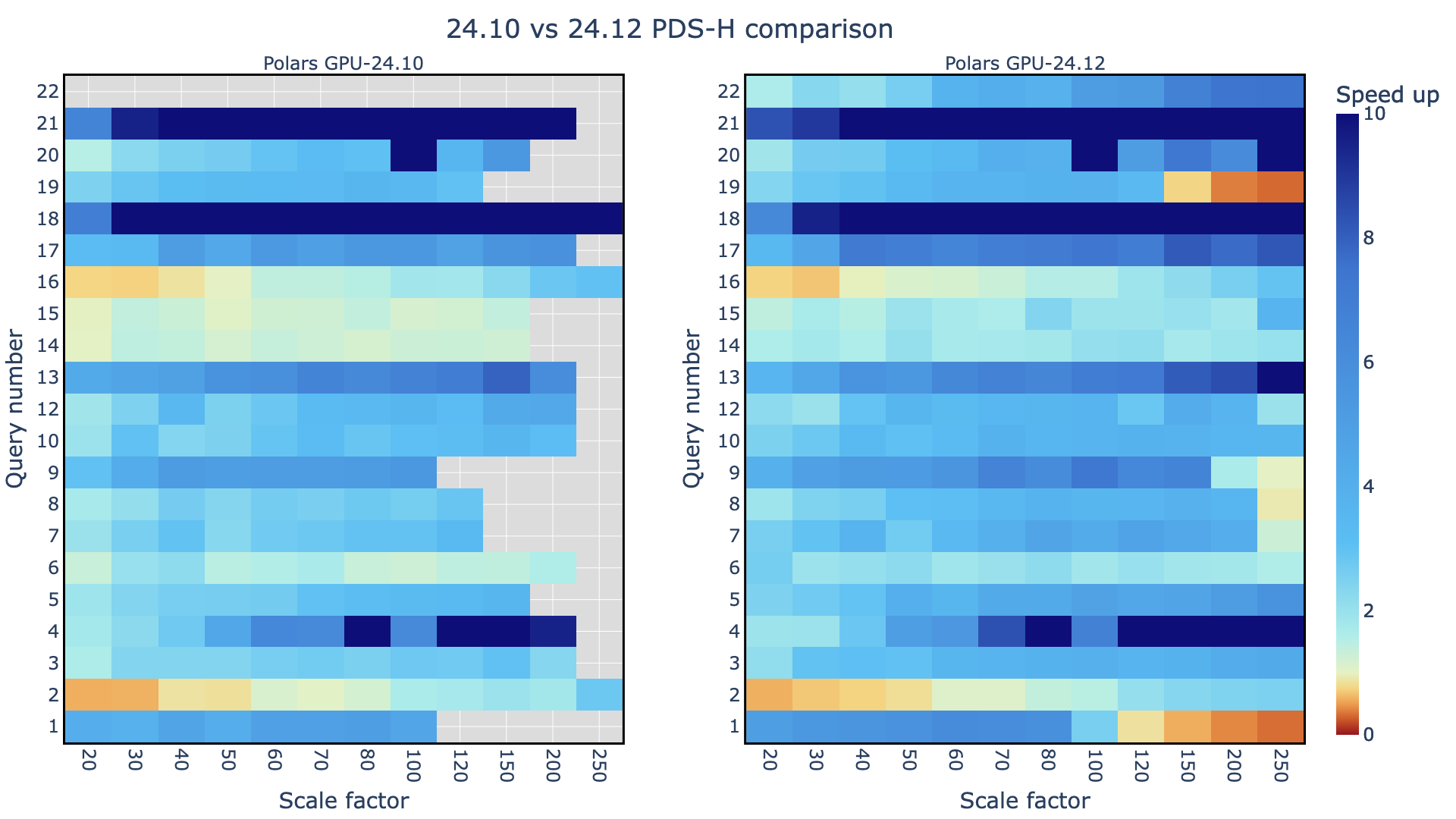
При работе с большими наборами данных производительность ваших инструментов обработки данных становится критически важной. Polars, библиотека с открытым исходным кодом для манипуляции данными, известная своей быстротой и эффективностью, предлагает GPU-ускоренный backend, основанный на cuDF, который может значительно повысить производительность.
Тем не менее, для полного использования мощности GPU backend Polars важно оптимизировать процесс загрузки данных и эффективно управлять памятью, необходимой для рабочего процесса. С развитием GPU backend стали доступны дополнительные техники для поддержания высокой производительности по мере увеличения размера набора данных при использовании Parquet reader на GPU. Существующий Parquet reader на GPU в Polars (до версии 24.10) не масштабировался для больших размеров наборов данных.
В этом посте рассматривается, как обработка данных с помощью читателя Parquet с разбивкой на части, в сочетании с Унифицированной Виртуальной Памятью (UVM), может превзойти как обычные нерезервируемые читатели, так и подходы на основе CPU.
Проблемы с факторами масштабируемости и нерезервируемыми читателями
С увеличением фактора масштабируемости (SF) нерезервируемый GPU reader Polars (24.10) часто страдает. За пределами SF200 производительность значительно ухудшается. В некоторых случаях, таких как Запрос 9, нерезервируемый GPU reader выдает ошибку даже до достижения SF50. Это ограничение возникает из-за нехватки памяти при загрузке больших файлов Parquet в память GPU. Пропущенные данные в графике нерезервируемого Parquet reader подчеркивают ошибки переполнения памяти (OOM), возникающие при более высоких факторах масштабируемости.

Улучшение ввода-вывода и пиковая память с помощью чтения Parquet с разбивкой на части
Чтобы преодолеть эти ограничения памяти, становится необходимым использование читателя Parquet с разбивкой на части. Читая файл Parquet маленькими частями, уменьшается объем занимаемой памяти, что позволяет Polars GPU обрабатывать большие объемы данных. Использование читателя Parquet с разбивкой на части с лимитом чтения в 16 ГБ позволяет выполнять больше факторов масштабируемости по сравнению с нерезервируемым читателем для любого данного запроса. Для Запроса 9 разбиение на части с 16 ГБ или 32 ГБ необходимо для выполнения и достижения лучшей пропускной способности.

Чтение еще больших наборов данных с помощью UVM
Хотя чтение с разбивкой на части улучшает управление памятью, интеграция UVM выводит производительность на новый уровень. UVM позволяет GPU получать доступ к системной памяти напрямую, что дополнительно облегчает ограничения памяти и улучшает эффективность передачи данных.
Для сравнения: чтение с разбивкой на части без UVM сталкивается с ошибкой OOM до достижения SF100. Чтение с разбивкой на части с UVM позволяет успешно выполнять запросы на более высоких факторах масштабируемости, но пропускная способность при этом снижается.
Рисунок 3 показывает явное преимущество. Значительно больше факторов масштабируемости успешно выполняются с читателем Parquet с разбивкой на части и включенным UVM по сравнению с нерезервируемым читателем Parquet.

Стабильность и пропускная способность
При выборе оптимального pass_read_limit важно учитывать баланс между стабильностью и пропускной способностью. Рисунки 1-3 предполагают, что 16 ГБ или 32 ГБ pass_read_limit является наилучшей комбинацией стабильности и пропускной способности.
- 32 ГБ
pass_read_limit: Все запросы были успешными, за исключением Запросов 9 и 19, которые завершились ошибками OOM - 16 ГБ
pass_read_limit: Все запросы были успешными
GPU с разбиением на части против CPU
Когда наблюдаемая пропускная способность каждого запроса обычно остается выше, чем у CPU Polars, это позволяет завершить множество запросов, которые не завершаются без разбивки. Кажется разумным использование 16 ГБ или, возможно, 32 ГБ pass_read_limit. Установки в 16 ГБ или 32 ГБ pass_read_limit обеспечивают успешное выполнение при более высоких факторах масштабируемости по сравнению с нерезервируемым Parquet.
Заключение
Для Polars GPU читатель Parquet с разбивкой на части и UVM часто лучше, чем CPU Polars и нерезервируемый читатель Parquet, особенно при работе с большими наборами данных и высокими факторами масштабируемости. Оптимизировав процесс загрузки данных, вы можете раскрыть весь потенциал Polars GPU и достичь значительного роста производительности. В рамках последней версии cudf-polars (24.12 и выше) читатель Parquet с разбивкой на части и UVM являются стандартным подходом для чтения файла Parquet. Это привело к улучшениям, представленным выше для всех запросов и факторов масштабируемости.
Чтобы начать работу, установите cuDF Polars.
Связанные ресурсы
- Курс DLI: Ускорьте операцию с DataFrame с помощью RAPIDS cuDF
- Сессия GTC: Ускоренная табличная обработка с Polars и RAPIDS
- Сессия GTC: Внимание к деревьям: Масштабируемая декодировка трансформера с длинным контекстом на кластерах GPU
- Сессия GTC: ACGT: Супербыстрая конверсия битов в базы
- SDK: RAPIDS
- Вебинар: Внутренности ускоренного Polars GPU Engine
Об авторах

О Преме Сагаре Гали
Прем Сагар Гали – старший инженер по системному программному обеспечению в NVIDIA, проживает в Остине, штат Техас, специализируется на разработке программного обеспечения для науки о данных для RAPIDS AI. У него степень магистра в области компьютерных наук из Технического университета Джорджии.Посмотреть все посты Према Сагара Гали

О Брендоне Миллере
Брендон Миллер – инженер-программист, который работает в NVIDIA около двух с половиной лет, в основном поддерживает библиотеку cuDF для Python. В последнее время его работа сосредоточена на компиляции Python-кода для выполнения на GPU, особенно в контексте пользовательских функций. Его образование связано с вычислительной физикой и высокопроизводительными вычислениями.Посмотреть все посты Брендона Миллера
