Компания NVIDIA и команда PyTorch в Meta объявили о революционном сотрудничестве, которое приводит возможности федеративного обучения (FL) на мобильные устройства благодаря интеграции NVIDIA FLARE и ExecuTorch.
NVIDIA FLARE — это универсальный, открытый и расширяемый SDK, который позволяет исследователям и специалистам по данным адаптировать существующие рабочие процессы машинного и глубокого обучения к федеративной парадигме. Он также позволяет разработчикам платформ создавать безопасные предложения, которые обеспечивают соблюдение конфиденциальности для распределенного многостороннего сотрудничества.
ExecuTorch — это комплексное решение для обеспечения возможностей инференса и обучения на устройствах с низкой мощностью в мобильных и крайних устройствах. Он является частью экосистемы PyTorch Edge и позволяет эффективно развертывать различные модели PyTorch на краевых устройствах.
Объединив эти два решения, мы предлагаем вам возможность использовать силу FL на мобильных устройствах, обеспечивая при этом конфиденциальность пользователей и безопасность данных. Для обеспечения кросс-устройственного FL есть два ключевых компонента:
- Среда FL, способная организовывать правильный поток обучения с пулом участников, состоящим из миллионов устройств.
- Эффективный рабочий процесс обучения на устройстве, который желательно легко перенести из вашей существующей среды разработки.
Сотрудничество между NVIDIA FLARE и ExecuTorch позволяет вам теперь определять архитектуру вашей модели и параметры обучения, используя знакомый код PyTorch, и переносить его в парадигму кросс-устройственного FL:
- NVIDIA FLARE управляет процессом кросс-устройственного FL с новыми модулями, предназначенными для краевых приложений, как для федеративного рабочего процесса, так и для разработки на устройстве.
- ExecuTorch обеспечивает обучение на стороне устройства и легкую миграцию от существующих решений PyTorch.
Для поддержки развертываний большого масштаба NVIDIA FLARE реализует иерархическую архитектуру FL, обеспечивающую эффективное управление большим количеством краевых устройств. Это решение гарантирует надежное и масштабируемое обучение моделей на распределенных мобильных устройствах, сохраняя все данные локально.
NVIDIA FLARE и ExecuTorch демократизируют обучение AI на краевых мобильных устройствах, делая его более доступным и эффективным, при этом сохраняя конфиденциальность в децентрализованной AI:
- Легкость в разработке: Абстрактная сложность устройства, управление аппаратным обеспечением, операционными системами, ML-фреймворками и языками программирования для бесшовного FL на мобильных устройствах.
- Упрощенное прототипирование: Симулятор устройств для имитации большого количества устройств.
- Готовое к индустрии федеративное развертывание: Система кросс-устройственного FL, поддерживающая большое количество устройств.
С этой архитектурой специалисты по данным могут сосредоточиться только на определении архитектуры моделей и параметров обучения в PyTorch, а также на проектировании федеративных потоков данных.
Совместное обучение моделей на распределенных краевых устройствах
Многие модели AI и приложения полагаются на повседневные данные, которые генерируются на краевых устройствах в повседневной жизни людей: например, предсказание текста и распознавание речи, автоматизация умного дома, автономное вождение, прогнозирование движения и обнаружение мошенничества для финансовых услуг. С использованием миллионов устройств с поддержкой AI значительная часть данных, используемых в AI, будет генерироваться на крае.
В отличие от специализированных наборов данных, таких как в корпоративных учреждениях — обычно кураторных, структурированных, помеченных в контролируемых условиях и хранящихся в централизованных хранилищах — повседневные данные на краевых устройствах являются высоко динамичными, подверженными влиянию поведения отдельных пользователей, факторов окружающей среды и специфических условий на гетерогенных устройствах.
Обучение моделей AI обычно предпочитает стабильный доступ к данным, быстрые каналы связи, обилие вычислительных ресурсов и контролируемое разнообразие данных. Для повседневных данных с такой динамичной и распределенной природой базовым и простым решением будет сбор данных из различных источников в центральное место для обучения.
Однако приложения, работающие на крае, обычно ограничены строгими требованиями конфиденциальности и практическими ограничениями, что делает централизованное обучение невозможным.
В этом случае FL на распределенных краевых устройствах становится потенциальным решением. Тем не менее, по-прежнему сложно совместно обучать надежные модели AI на основе данных, собранных на краевых устройствах, из-за периодического подключения устройств, ограниченной пропускной способности связи, переменной мощности устройств и высокогоризонтального распределения данных.
Чтобы правильно решить эти проблемы и обеспечить эффективное обучение моделей AI распределенным образом, хорошо спроектированная структура FL с функциональностью на устройстве может сыграть важную роль в эффективном использовании всех данных из разнообразного набора устройств.
Такая структура FL должна обладать возможностью справляться со следующими задачами:
- Большим масштабом участвующих устройств, поскольку размер пула кандидатов часто составляет миллионы.
- Разными операционными системами и аппаратными средами, что приводит к высокой сложности программирования устройств.
- Проблемами, возникающими из-за ограниченной вычислительной мощности и пропускной способности связи.
- Проблемами, вызванными подключением, такими как устройства, которые могут присоединяться и покидать сеть в любое время.
Таким образом, структура должна правильно организовывать обновления модели и агрегирование аспектов федеративного потока и справляться с этими проблемами.
| Проблема | Решение |
| Большое количество устройств | NVIDIA FLARE разработала иерархический механизм связи и агрегирования, который использует логическую древовидную структуру для достижения экспоненциальной эффективности при работе с тысячами одновременных подключений. |
| Разные операционные системы и аппаратные среды | Meta ExecuTorch достигает устранения препятствий для кроссплатформенного развертывания с модулями NVIDIA FLARE на крае. |
| Ограниченная вычислительная мощность и пропускная способность связи | NVFLARE позволяет вам использовать эффективные модели, сжимать обновления с длительным локальным обучением и либо оптимизировать выбор клиентов, либо использовать иерархическое FL для снижения затрат на вычисления, связь и пропускную способность. |
| Подключение | NVIDIA FLARE предоставляет надежные решения и гибкость для учета различных сценариев и вариантов использования. |
Иерархическое FL для кросс-устройственных приложений
С одноуровневым потоком FL глобальный сервер напрямую связывается с клиентами и использует простую логику для сбора и агрегирования обновлений модели. Однако для случаев использования кросс-устройств, где потенциально может быть десятки тысяч одновременных устройств из пула миллионов участников, основная одноуровневая структура связи не может функционировать.

NVIDIA FLARE разработала иерархическую систему FL с архитектурой в виде дерева (Рисунок 1):
- Сервер: Обеспечивает функции общей оркестрации, глобальной оценки, подготовки работ и заданий и т. д.
- Агрегаторы: Выполняют маршрутизацию задач от сервера к конечным узлам и агрегирование результатов от конечных узлов обратно к серверу.
- Конечные узлы: Единственные, которые взаимодействуют с краевыми устройствами. Устройства подключаются к конечным узлам через веб-шлюзы, которые развертываются с несколькими экземплярами для масштабируемости веб-инфраструктуры.
Добавив несколько уровней агрегирования, мы оптимизировали доступное и надежное распределение нагрузки на каждом узле системы. С такой надежной иерархией продвинутые алгоритмы FL могут быть легко реализованы и масштабированы. Эта древовидная иерархия логична, и физические соединения и маршруты связи между узлами могут быть дополнительно оптимизированы в зависимости от условия сети.
Используя веб-шлюзы через HTTPS, мы гарантируем, что каждое устройство правильно подключено с шифрованием и что его данные передаются соответствующим клиентам FL безопасно для обработки. Веб-шлюз также управляет регистрацией устройств, управлением сессиями и балансировкой нагрузки, оптимизируя подключение для развертываний большого масштаба. Этот подход предлагает масштабируемое решение для поддержки потенциально миллионов краевых устройств или мобильных телефонов в сценарии FL.

На рисунке 2 показано, как NVIDIA FLARE и ExecuTorch работают вместе поэтапно для обеспечения кросс-устройственного FL:
- Контроллер FLARE на сервере сначала подготавливает задачу, содержащую глобальную модель, и распределяет её через иерархическую систему, пока она не достигнет конечного узла.
- EdgeTaskExecutor FLARE на конечном узле обрабатывает задачу, экспортирует глобальную модель в формат ExecuTorch (если контроллер этого не сделал) и отправляет задачу отдельным устройствам через веб-шлюзы.
- На устройстве модуль
DeviceNVIDIA FLARE соединяет систему FL и рабочие процессы обучения на устройстве, где ExecuTorch загружает полученную глобальную модель, выполняет обучение на устройстве с локальными данными и отправляет новую модель обратно модулюDevice. - Модуль
Deviceзатем подготавливает сообщение, содержащее локальные обновления модели (разница между глобальной моделью и новой моделью, возможно, дополненная механизмами защиты конфиденциальности) и отправляет обновления обратно к EdgeTaskExecutor FLARE. - EdgeTaskExecutor FLARE затем обрабатывает полученные обновления и отправляет их через иерархическую систему, где обновления из разных источников агрегируются по уровням.
- При получении агрегированных обновлений модели на верхнем уровне контроллер FLARE оценивает и подготавливает новую глобальную модель для следующего задания.
Легкость в разработке кросс-устройственного федеративного потока
С поддержкой от NVIDIA FLARE и ExecuTorch мы предоставляем упрощенный кросс-устройственный поток FL для вас, обеспечивая эффективный общий рабочий процесс с настраиваемыми компонентами, чтобы вы могли сосредоточиться на инновациях, не беспокоясь о разработке основ инфраструктуры.
Сторона устройства, модуль Device устанавливает основной рабочий процесс обучения (например, Objective-C на iOS), который служит мостом между системой FL и обучением на устройстве, предоставляя вам настраиваемые параметры и настройки конфиденциальности. Он управляет гетерогенным аппаратным обеспечением, операционными системами, ML-фреймворками и языками программирования, абстрагируя сложность устройств.
Используя ExecuTorch, вы сосредотачиваетесь на разработке новых моделей и рецептов обучения, которые затем могут быть легко перенесены на платформу устройства.
На стороне федеративного потока вы определяете настраиваемые схемы FL, например, синхронизированные или асинхронизированные с API контроллера NVIDIA FLARE. Настраиваемые агрегаторы предлагают разнообразные варианты, которые наилучшим образом соответствуют нуждам конкретных учебных целей. Коллекция широко используемых контроллеров и агрегаторов от NVIDIA FLARE может быть применена по умолчанию.
Все остальное, от распределения глобальной модели и выполнения локальных задач до сбора обновлений модели для создания новых глобальных моделей, осуществляется автоматически, освобождая вас от сложных деталей реализации.
Кроме того, мы предоставляем симуляторы устройств для проведения локальных FL-имитаций для мобильных приложений. Это обеспечивает гибкий механизм для прототипирования, охватывающий обучение моделей на основе выбранных пользователем рецептов обучения.
Например, вы можете протестировать тренер на базе PyTorch и сравнить его с версией на базе ExecuTorch, чтобы убедиться, что развертываемое решение ExecuTorch соответствует аналогичной модели на PyTorch. Вы также можете протестировать различные агрегаторы для проверки их производительности в реалистичных настройках.
Другими словами, вы можете создать прототип ваших кросс-устройственных потоков FL, используя Python, и провести локальные имитации для всего исследования FL таким же образом, как это делается для других процессов обучения моделей с использованием NVIDIA FLARE.
Затем вы можете легко перенести и развернуть прототип в реальную систему кросс-устройственного FL. Нет необходимости переключаться на разработку мобильных платформ на других языках (таких как Objective-C, Swift, Java или Kotlin) или беспокоиться о подключении к сети и маршрутизации. NVIDIA FLARE и ExecuTorch вместе обрабатывают все требования к обучению на конкретных устройствах и федеративные оркестрации.
Запуск примера NVFlare Mobile
Чтобы помочь вам начать, мы предоставили примеры для демонстрации этого процесса имитации. В Примере запуска NVFlare Mobile мы охватываем следующие приложения по двум схемам обучения:
hello_mobile: Простая задача с списком чисел для тестирования краевых функций, включая иерархическое агрегирование и обработку задач. Демонстрирует федеративный процесс.xor_mobileиxor_mobile_pt: Обучение суперлегкой нейронной сети для простой логической задачи XOR с фиксированными данными для всех участников, используя и ExecuTorch, и обычные тренеры PyTorch. Демонстрирует поток с обучением нейронной сети.cifar10_mobileиcifar10_mobile_pt: Обучение сверточной нейронной сети для стандартной задачи классификации CIFAR-10. Оба варианта ExecuTorch и PyTorch предоставляются. В этом случае каждый участник обучается на различных подмножествах CIFAR-10, имитируя более реалистичное совместное использование между устройствами.
Для развертывания в реальном мире процесс включает три части:
- Настройка NVIDIA FLARE
- Включение обучения на краевых устройствах через ExecuTorch
- Проведение сессий FL
Исследование начинается с настройки системы NVIDIA FLARE, включая ее настройку и установку веб-шлюзов, что может быть так же просто, как две команды:
python nvflare/edge/tree_prov.py -r /tmp -p edge_example -d 1 -w 2 python nvflare/edge/web/routing_proxy.py 5000 /tmp/edge_example/lcp_map.json
Дополнительную информацию смотрите в Примере запуска NVFlare Mobile.
После настройки окружения запустите каждый узел с помощью сценария в их стартовых комплектов:
./start.sh
На стороне краевого устройства мы разработали демонстрационное iOS приложение, чтобы продемонстрировать эту возможность. В этом приложении вы настраиваете IP-адрес прокси-сервера и номер порта, после чего запускаете процесс обучения (Рисунок 3).
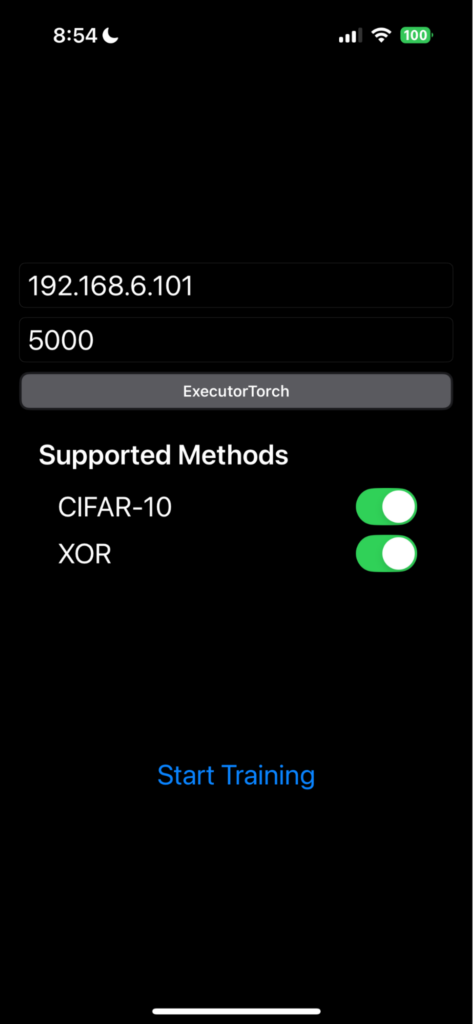
Приложение затем подключается к системе FL через прокси-сервер (Рисунок 1) и ожидает назначения задачи.
Обучение начинается только после того, как задание было предоставлено системе NVFlare. Контроллер назначает конкретную задачу на краевое устройство через механику (Рисунок 2).
Чтобы запустить сессию FL, администратор проверяет глобальные настройки (например, формат модели и веса) и предоставляет задание, чтобы начать обучение NVIDIA FLARE, как обычно, в консоли администратора NVFlare:
submit_job cifar10_mobile_et
Остальная часть федеративной оркестрации автоматически обрабатывается NVIDIA FLARE, а локальное обучение на устройстве выполняется ExecuTorch.
Резюме
Сотрудничество команды NVIDIA FLARE и команды Meta PyTorch представляет собой значительное продвижение в мобильном FL, предлагая целостный подход для разработки решений FL для кросс-устройств. Этот поток помогает справляться со сложностями мобильного развертывания и федеративного обучения за кулисами.
Благодаря иерархической архитектуре NVIDIA FLARE платформа может эффективно управлять миллионами краевых устройств, что делает мобильный FL практичным и доступным. Специалисты по данным могут сосредотачиваться на своей ключевой области, определяя модели и параметры обучения на Python, в то время как NVIDIA FLARE и ExecuTorch обрабатывают сложные детали мобильного развертывания, федеративной оркестрации и масштабируемости обучения. Этот инновационный подход сохраняет конфиденциальность данных и безопасность, обеспечивая при этом эффективное обучение моделей на распределенных устройствах.
Сотрудничество между NVIDIA и командой PyTorch в Meta является значительным шагом вперед в демократизации FL для мобильных приложений, открывающим новые возможности для разработки децентрализованного AI на крае с соблюдением конфиденциальности. Обе команды продолжают сотрудничество, чтобы улучшить это решение.
С целью демократизации обучения на устройствах на различных устройствах мы начали с iOS и продолжим с Android и другими краевыми устройствами.
Для получения дополнительной информации смотрите следующие ресурсы:
- /NVFlare уроки на GitHub
- /NVIDIA/NVFlare примеры на крае на GitHub
- Портал разработчиков NVIDIA FLARE
- Федеративное обучение в медицинской визуализации: повышение конфиденциальности данных и развитие здравоохранения сессия GTC 2025
Чтобы связаться с командой NVIDIA FLARE, напишите на [email protected].
Благодарности
Благодарим команду PyTorch в Meta за помощь с данной публикацией.
