Запросы на вычислительные ресурсы для моделей большого языка (LLM) стремительно растут, что обусловлено сочетанием увеличивающихся размеров моделей, требований к задержкам в реальном времени и, что недавно появилось, рассуждениями ИИ. В то же время, по мере роста внедрения ИИ, возможность ИИ-фабрики обслуживать как можно больше пользователей при этом обеспечивая хорошее качество обслуживания для каждого пользователя имеет решающее значение для максимизации создаваемой ею ценности. Достижение высокой пропускной способности вывода и низкой задержки вывода на последних моделях требует высокого уровня мастерства на всем технологическом уровне, охватывающем кремний, сетевые системы и программное обеспечение.
MLPerf Inference v5.0 является последней версией долгосрочного набора бенчмарков, который измеряет пропускную способность инференса для различных моделей и случаев использования. Впервые представленный в 2019 году, MLPerf Inference постоянно обновляется новыми моделями и сценариями, чтобы обеспечить его полезность как инструмента для измерения производительности инференса платформ ИИ.
Этот раунд добавляет три новых бенчмарка:
- Llama 3.1 405B: Плотная LLM с 405 миллиардами параметров. Для сценария сервера бенчмарк устанавливает требования к задержке: 6 секунд до первого токена и 175 мс за токен.
- Llama 2 70B Interactive: Плотная LLM с 70 миллиардами параметров. Эта нагрузка основана на той же модели Llama 2 70B, которая была впервые представлена в MLPerf Inference v4.0, но имеет более строгие ограничения на задержку: 450 мс до первого токена и 40 мс за токен (25 токенов в секунду на пользователя).
- Сетевой граф внимания (R-GAT): Бенчмарк графовой нейронной сети (GNN). GNN применяются в широком спектре областей, включая анализ социальных сетей, открытие лекарств, обнаружение мошенничества и молекулярную химию.
Эти новые бенчмарки присоединяются к множеству возвращающихся бенчмарков, охватывающих разнообразный набор моделей и случаев использования: ResNet-50, RetinaNet, 3D U-Net, DLRMv2, GPT-J, Stable Diffusion XL, Llama 2 70B и Mixtral 8x7B.
NVIDIA представила результаты по всем бенчмаркам в категории центров обработки данных, обеспечив выдающуюся производительность во всех направлениях, включая новые результаты производительности по недавно добавленным тестам Llama 3.1 405B, Llama 2 70B Interactive и GNN. В этом раунде NVIDIA также представила много результатов по архитектуре Blackwell, используя как NVIDIA GB200 NVL72, так и NVIDIA DGX B200, что привело к значительному увеличению скорости по сравнению с предыдущим поколением архитектуры NVIDIA Hopper. Hopper также продолжала обеспечивать отличную производительность на всех фронтах три года спустя после своего введения, благодаря программным улучшениям, которые продолжают увеличивать производительность для этой семейства GPU.
В этом посте мы более подробно рассмотрим результаты производительности и предоставим дополнительные детали о полномасштабных инновациях, которые сделали это возможным.
Blackwell устанавливает новый стандарт производительности в MLPerf
Архитектура NVIDIA Blackwell, представленная на NVIDIA GTC 2024, находится в полном производстве, с доступностью от основных облачных сервисов и широкого числа производителей серверов. Blackwell включает многие архитектурные инновации, включая второй поколение Transformer Engine, пятую генерацию NVLink, точности FP4 и FP6 и многие другие, что обеспечивает значительно более высокую производительность как для обучения, так и для инференса.
Платформа Blackwell доступна в нескольких различных формах систем, чтобы соответствовать широкому диапазону требований к развёртыванию в центрах обработки данных. NVIDIA представила результаты, используя как GB200 NVL72, систему в масштабе стойки с 36 процессорами Grace и 72 GPU Blackwell, полностью соединённых с помощью NVLink и NVSwitch, так и DGX B200, который включает восемь GPU Blackwell, соединённых с помощью NVLink и NVSwitch.
Кроме того, в этом раунде результаты Blackwell по Llama 3.1 405B, Llama 2 70B Interactive, Llama 2 70B и Mixtral 8x7B использовали второй поколение Transformer Engine с FP4 Tensor Cores, программное обеспечение NVIDIA TensorRT-LLM для эффективного выполнения моделей, и TensorRT Model Optimizer для FP4 квантизации. Сочетание этих технологий позволило использовать точность FP4, которая обеспечивает в два раза большую пиковую пропускную способность на Blackwell по сравнению с FP8, обеспечивая при этом требования точности бенчмарка.
По бенчмарку Llama 3.1 405B, GB200 NVL72 обеспечила производительность на 3.4x выше на GPU по сравнению с NVIDIA H200 Tensor Core системой с восемью GPU.
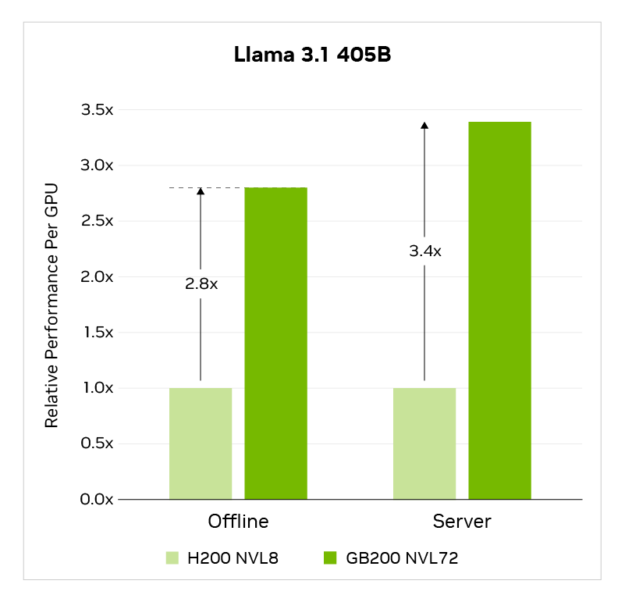
Результаты MLPerf Training v5.0 получены от http://www.mlcommons.org 2 апреля 2025 года из следующих записей: 5.0-0058, 5.0-0060. Производительность на GPU не является основным показателем MLPerf Inference v5.0 и получается путем деления отчётной пропускной способности на количество ускорителей. Название и логотип MLPerf являются товарными знаками Ассоциации MLCommons в Соединенных Штатах и других странах. Все права защищены. Неавторизованное использование строго запрещено. См. http://www.mlcommons.org для получения дополнительной информации.
На уровне системы GB200 NVL72 увеличивает производительность до 30 раз в результате сочетания более высокой производительности на GPU и 9 раз большего количества GPU в системе, все соединены в одном домене NVLink с помощью NVLink и NVLink Switch.
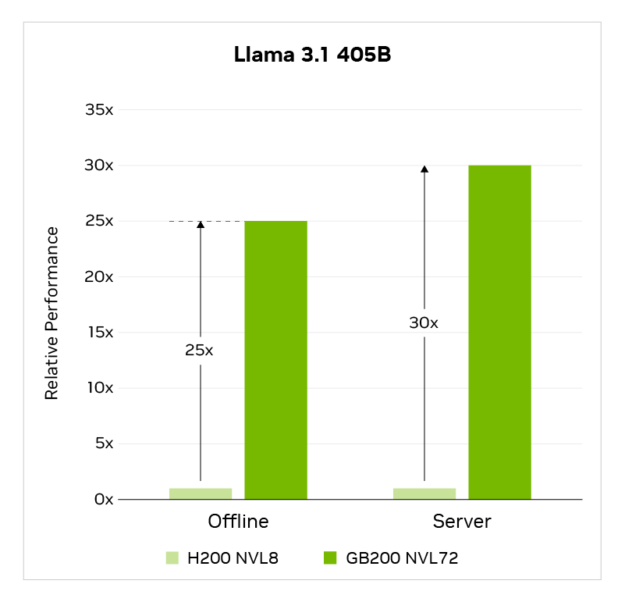
Результаты MLPerf Training v5.0 получены от http://www.mlcommons.org 2 апреля 2025 года из следующих записей: 5.0-0058, 5.0-0060. Название и логотип MLPerf являются товарными знаками Ассоциации MLCommons в Соединенных Штатах и других странах. Все права защищены. Неавторизованное использование строго запрещено. См. http://www.mlcommons.org для получения дополнительной информации.
Кроме того, NVIDIA провела бенчмарк Llama 2 70B из MLPerf Inference v4.1 на GB200 NVL72, достигнув непроверенного результата в 869,203 токенов в секунду.
По бенчмарку Llama 2 70B Interactive система B200 с восемью GPU достигла 3.1x большей пропускной способности по сравнению с отправкой NVIDIA, использующей восемь GPU H200.
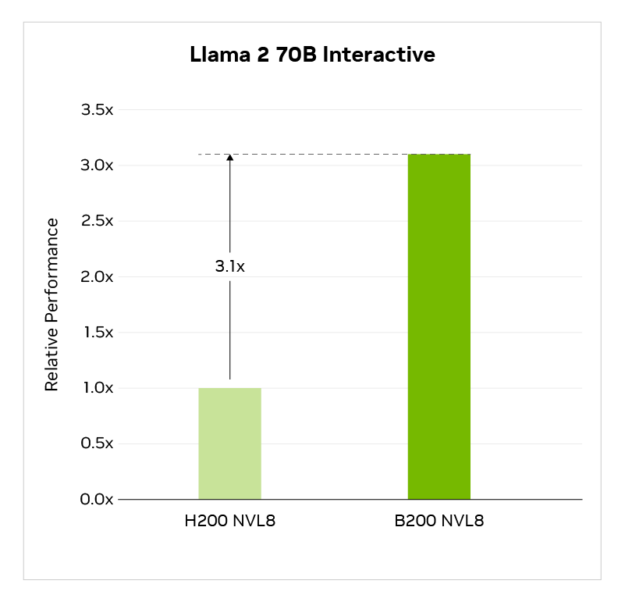
MLPerf Inference v5.0, Закрыто, Центр обработки данных. Результаты получены от www.mlcommons.org 2 апреля 2025 года. Результаты из следующих записей: 5.0-0056, 5.0-0060. Название и логотип MLPerf являются товарными знаками Ассоциации MLCommons в Соединенных Штатах и других странах. Все права защищены. Неавторизованное использование строго запрещено. См. http://www.mlcommons.org для получения дополнительной информации.
B200 также обеспечила значительные ускорения по Llama 2 70B, Mixtral 8x7B и Stable Diffusion XL.
| Бенчмарк | 8x GPU Blackwell Сервер | Офлайн |
8x GPU H200 Сервер | Офлайн |
Ускорения Blackwell Сервер | Офлайн |
| Llama 2 70B Токены/сек |
98,443 | 98,858 | 33,072 | 34,988 | 3x | 2.8x |
| Mixtral 8x7B Токены/сек |
126,845 | 128,148 | 61,802 | 62,630 | 2.1x | 2.1x |
| Stable Diffusion XL Образцы/сек | Запросы/сек |
28.44 | 30.38 | 18.30 | 18.99 | 1.6x | 1.6x |
MLPerf Inference v5.0, Закрыто, Центр обработки данных. Результаты получены от www.mlcommons.org 2 апреля 2025 года. Результаты из следующих записей: 5.0-0056, 5.0-0060. Название и логотип MLPerf являются товарными знаками Ассоциации MLCommons в Соединенных Штатах и других странах. Все права защищены. Неавторизованное использование строго запрещено. См. http://www.mlcommons.org для получения дополнительной информации.
Hopper продолжает обеспечивать выдающуюся производительность
Платформа Hopper, впервые представленная в марте 2022 года, продолжала обеспечивать выдающуюся производительность инференса по каждому бенчмарку в MLPerf Inference v5.0, включая недавно добавленные Llama 3.1 405B и Llama 2 70B Interactive.
Поскольку облачные сервисы и предприятия стремятся максимизировать полезный срок службы своих инвестиции в ускоренную инфраструктуру, способность платформы поддерживать новые модели ИИ и варианты использования имеет решающее значение. В то же время пропускная способность инференса ИИ-фабрики напрямую зависит от её пропускной способности инференса – увеличением пропускной способности для данной модели на той же инфраструктуре с помощью нового программного обеспечения можно снизить затраты на генерацию токенов и увеличить потенциал дохода от ИИ.
По бенчмарку Llama 2 70B пропускная способность NVIDIA H100 Tensor Core GPU, увеличенная благодаря программным оптимизациям, возросла до 1.5x за последний год. Эти оптимизации включают оптимизации GEMM и ядер внимания, расширенные слияния ядер, упрощенную предварительную заполняемость и многое другое. Кроме того, улучшения конвейерного параллелизма в TensorRT-LLM сыграли важную роль, что способствовало увеличению пропускной способности Llama 2 70B на H100.
Архитектура Hopper включает NVLink Switch, что позволяет каждому GPU общаться с любым другим GPU на полной ширине канала, независимо от количества общающихся GPU. Это предоставляет разработчикам гибкость в выборе оптимальных отображений параллелизма для максимизации пропускной способности при заданных ограничениях по задержке. Связь через NVLink Switch может быть дополнительно перекрыта с вычислениями GEMM на тонком уровне, что помогает увеличить пропускную способность Llama 3.1 405B на H200 NVL8.
Результатом этих постоянных оптимизаций является то, что Hopper достиг отличной производительности на последних и наиболее сложных нагрузках MLPerf, таких как Llama 3.1 405B и Llama 2 70B Interactive.
Платформа NVIDIA также была единственной, кто представил результаты по бенчмарку Mixtral 8x7B, который использует архитектуру модели смесь экспертов (MoE), при этом производительность Hopper увеличилась по сравнению с предыдущим раундом. А производительность по бенчмарку GPT-J снова увеличилась, что привело к совокупному улучшению Hopper с момента первого внедрения бенчмарка до 2.9x в оффлайн-сценарии и 3.8x в серверном сценарии.
Подводя итоги
Платформа NVIDIA Hopper обеспечивает лидирующие показатели в обучении, как показано в самом последнем раунде MLPerf Training, а также в MLPerf Inference, как показывают эти результаты. Hopper остается передовой платформой три года после своего первого запуска, и с продолжением полной оптимизации она продолжает обеспечивать увеличение производительности для существующих случаев использования ИИ и поддерживать новые, предлагая высокую долговечность.
NVIDIA Blackwell устанавливает новый стандарт производительности и энергоэффективности — ключевых факторов доходов и прибыльности ИИ-фабрики. Обеспечивая значительное увеличение производительности для существующих нагрузок и позволяя достичь ещё больших результатов для более требовательных сценариев, включая самые последние модели рассуждений, Blackwell открывает новые горизонты в области инноваций в ИИ.
И NVIDIA масштабирует рассуждения ИИ с помощью Dynamo, который работает на GPU Hopper и Blackwell.
Благодарности
Работа многих сотрудников NVIDIA привела к достижению этих выдающихся результатов. Мы хотели бы поблагодарить за неустанные усилия Кефенга Дуана, Шенглиана Сю, Иилина Чана, Роберта Овермана, Шобсита Верму, Вирата Чандру, Цзихао Кунга, Тин-Ина Лая и Элис Ченг, среди многих других.
Результаты получены с помощью кода NVIDIA MLPerf v4.1 с TensorRT-LLM 0.18.0.dev. Непроверенный MLPerf v4.1 Inference Closed Llama 2 70B оффлайн. Результат не подтвержден Ассоциацией MLCommons. Непроверенные результаты не прошли проверку MLPerf и могут использовать методологии измерений и/или реализации нагрузки, которые не соответствуют спецификации MLPerf для проверенных результатов. Название и логотип MLPerf являются зарегистрированными и незарегистрированными товарными знаками Ассоциации MLCommons в Соединенных Штатах и других странах. Все права защищены. Неавторизованное использование строго запрещено. См. www.mlcommons.org для получения дополнительной информации.