Новейшее поколение популярных моделей Llama AI теперь доступно с Llama 4 Scout и Llama 4 Maverick. Ускоренные с помощью программного обеспечения с открытым исходным кодом от NVIDIA, они могут достигать более 40K токенов вывода в секунду на графических процессорах NVIDIA Blackwell B200 и доступны для испытаний как микросервисы NVIDIA NIM.
Модели Llama 4 теперь являются многомодальными и многоязычными, использующими архитектуру с миксом экспертов (MoE). Они предоставляют разнообразные многомодальные возможности, способствуя росту масштабов, скорости и эффективности, которые позволяют создавать более персонализированные впечатления.
Llama 4 Scout – это модель с 109 миллиардами параметров, 17 миллиардов активных на токен, с конфигурацией из 16 экспертов и длиной контекста 10 миллионов токенов, оптимизированная и квантованная до int4 для одного графического процессора NVIDIA H100. Это открывает различные возможности использования, включая многодокументное суммирование, анализ обширной пользовательской активности для персонализированных задач и рассуждения над огромными кодовыми базами.
Llama 4 Maverick – это модель с 400 миллиардами параметров, 17 миллиардов активных на токен, с конфигурацией из 128 экспертов, принимающих контекст длиной 1 миллион токенов. Эта модель предоставляет высокопроизводительное понимание изображений и текста.
Оптимизировано для NVIDIA TensorRT-LLM
NVIDIA оптимизировала как модели Llama 4 Scout, так и Llama 4 Maverick для NVIDIA TensorRT-LLM. TensorRT-LLM – это библиотека с открытым исходным кодом, используемая для ускорения производительности вывода LLM для последних базовых моделей на графических процессорах NVIDIA.
Вы можете использовать TensorRT Model Optimizer, библиотеку, которая может рефакторить модели bfloat16 с последними алгоритмическими оптимизациями и техниками квантования, чтобы ускорить вывод с производительностью Blackwell FP4 Tensorcore, не влияя на точность модели.
На графическом процессоре Blackwell B200 TensorRT-LLM обеспечивает производительность более 40K токенов в секунду с оптимизированной NVIDIA FP8 версией Llama 4 Scout, а также более 30K токенов в секунду на Llama 4 Maverick.
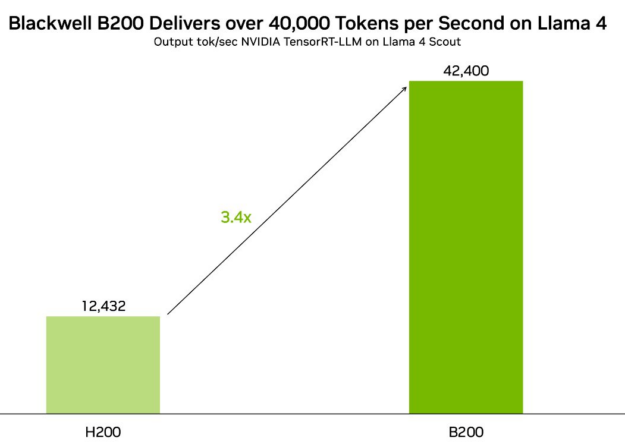
Blackwell обеспечивает значительные улучшения производительности благодаря архитектурным инновациям, включая второй поколение Transformer Engine, пятую генерацию NVLink и прецизионные значения FP8, FP6 и FP4, которые позволяют повысить производительность как для обучения, так и для вывода. Для Llama 4 эти усовершенствования обеспечивают в 3,4 раза большую пропускную способность и в 2,6 раза меньшие затраты на токен по сравнению с NVIDIA H200.
Последние оптимизации Llama 4 доступны в репозитории NVIDIA/TensorRT-LLM на GitHub.
Непрерывное сотрудничество Meta и NVIDIA
NVIDIA и Meta имеют долгую историю сотрудничества в продвижении открытых моделей. NVIDIA является активным участником проекта с открытым исходным кодом, что помогает вам эффективно работать, решая сложнейшие задачи и повышая производительность при снижении затрат.
Модели с открытым исходным кодом также способствуют прозрачности ИИ и позволяют пользователям широко делиться работами по безопасности и устойчивости ИИ. Эти открытые модели в сочетании с ускоренными вычислениями от NVIDIA предоставляют разработчикам, исследователям и бизнесу возможность ответственно innovate в различных приложениях.
Дополнительная настройка моделей Llama для повышения точности
Тонкая настройка моделей Llama осуществляется легко с помощью NVIDIA NeMo, всего комплекса, предназначенного для индивидуализации больших языковых моделей (LLM) с данными вашей компании.
Начните с курирования наборов данных для предварительного обучения или донастройки с помощью NeMo Curator, который помогает извлекать, фильтровать и дубликатировать структурированные и неструктурированные данные в больших масштабах. Затем используйте NeMo для эффективной донастройки моделей Llama с поддержкой таких техник, как LoRA, PEFT и полная настройка параметров.
После донастройки моделей вы можете оценить их производительность с помощью NeMo Evaluator, который поддерживает как отраслевые измерения, так и настраиваемые тестовые наборы, подходящие для вашего конкретного случая использования.
С NeMo предприятия получают мощный и гибкий рабочий процесс, чтобы адаптировать модели Llama для готовых к производству приложений ИИ.
Упрощение развертывания с NVIDIA NIM
Чтобы гарантировать, что предприятия могут воспользоваться ими, модели Llama 4 будут упакованы как микросервисы NVIDIA NIM, что облегчит их развертывание на любой инфраструктуре с ускорением GPU с гибкостью, конфиденциальностью данных и безопасностью корпоративного уровня.
NIM также упрощает развертывание благодаря поддержке стандартных API, поэтому вы можете быстро начать работу. Будь то LLM, модели зрения или многомодальный ИИ, NIM абстрагирует сложность инфраструктуры и обеспечивает плавное масштабирование через облака, центры обработки данных и периферийные среды.
Начните прямо сейчас
Попробуйте микросервисы Llama 4 NIM, чтобы поэкспериментировать с вашими данными и создать демонстрацию, интегрировав API-эндпоинт, размещенный NVIDIA, в ваше приложение.
