NVIDIA ACE представляет собой набор технологий для цифровых персонажей, который оживляет игровые персонажи и цифровых помощников с помощью генеративного ИИ. Модели ACE, работающие на устройстве, позволяют автономным игровым персонажам воспринимать свою среду, понимать многомодальные вводные данные, стратегически планировать набор действий и выполнять их в реальном времени, обеспечивая динамичные ощущения для игроков.
Для запуска этих моделей совместно с игровым двигателем NVIDIA In-Game Inferencing (NVIGI) SDK позволяет интегрировать ИИ-инференс непосредственно в C++ игры и приложения для оптимальной производительности и задержки.
В этом посте показывается, как NVIGI интегрируется с ACE для обеспечения бесшовного ИИ-инференса в разработке игр. Мы рассмотрим архитектуру NVIGI, ключевые функции и как начать создание автономных персонажей с помощью моделей NVIDIA ACE на устройстве.
NVIDIA ACE на устройствах
NVIDIA ACE предлагает речь, интеллект и анимацию на основе генеративного ИИ. Он предоставляет набор моделей ИИ, которые позволяют игровым персонажам воспринимать, размышлять и действовать на основе взаимодействий с игроком в режиме реального времени:
- Восприятие: Предстоящая модель NeMoAudio-4B-Instruct улучшает взаимодействие персонажей с большей контекстуальной осведомленностью из аудио. Вы можете легко интегрировать дополнительные многомодальные модели для дальнейшего расширения этих возможностей с помощью дополнительных сенсорных вводных данных.
- Когниция: Семейство малых языковых моделей Mistral-Nemo-Minitron-Instruct возглавляет рейтинги по возможностям следования инструкциям, позволяя персонажам точно выполнять роли.
- Память: Модели, такие как E5-Large-Unsupervised, позволяют персонажам вспоминать прошлые взаимодействия, обогащая погружение.
- Анимация: Анимация в реальном времени на основе ИИ, такая как Audio2Face, обеспечивает точную синхронизацию губ для динамичных и живых эмоций.
- Действие: Простые интерфейсы и пользовательская логика позволяют персонажам выполнять значимые действия, от выбора ответов в игре до реализации стратегических планов через принятие решений на основе моделей и подсказок.
Что такое NVIDIA In-Game Inferencing SDK?
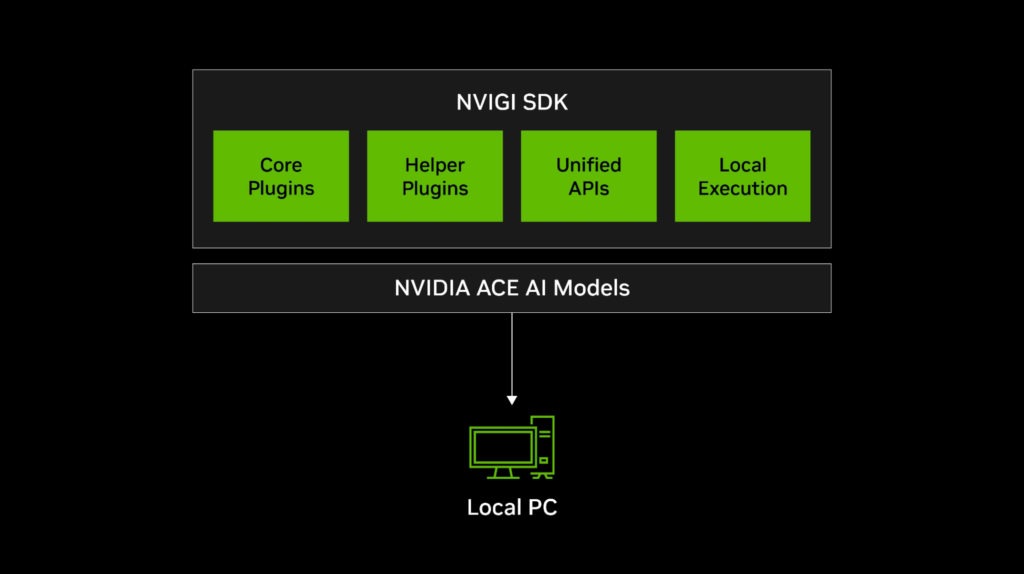
NVIGI SDK является оптимизированным для GPU менеджером инференса на основе плагинов, предназначенным для упрощения интеграции моделей ACE в игровые и интерактивные приложения. Он предлагает следующую функциональность:
- Гибкость плагинов: Легко добавляйте, обновляйте и управляйте ИИ-плагинами (ASR, языковые модели, встраивания).
- DLL для Windows: Упрощает рабочие процессы для C++ игр и приложений.
- Оптимизация GPU: Используйте технологию вычислений в графике (CIG) для эффективного ИИ-инференса наряду с графическими задачами.
Комбинируя NVIGI с ACE, вы можете создавать автономных персонажей с расширенными возможностями генеративного ИИ, такими как диалоги NPC в реальном времени, контекстная память и реалистичная анимация.
Как работает NVIGI
В своей основе архитектура NVIGI основана на модульных плагинах, которые позволяют гибко интегрировать различные функции ИИ:
- Основные плагины: Обеспечивают возможности ИИ, такие как автоматическое распознавание речи (ASR), генеративное размышление и извлечение встраиваний.
- Вспомогательные плагины: Обрабатывают такие утилиты, как управление GPU и сетевое взаимодействие.
- Унифицированные API: Упрощают управление плагинами и снижают сложность кода.
- Локальное и облачное выполнение: Поддерживает как инференс на устройстве (ЦП/ГП), так и облачные рабочие процессы ИИ.
Эти компоненты работают вместе, чтобы обеспечить бесшовный игровой опыт на основе ИИ. Например, представьте, что игрок задает вопрос NPC. NVIGI управляет автономным рабочим процессом, позволяя персонажам слушать, размышлять, говорить и анимировать в реальном времени.
Этот процесс проходит через несколько ключевых шагов:
- Слушайте пользователей с помощью ASR: NPC обрабатывает речь игрока с помощью NVIDIA Riva ASR, преобразуя произнесенные данные в текст для дальнейшего размышления.
- Генерируйте ответ с помощью SLM: Транскрибированный текст передается малой языковой модели (SLM), такой как Mistral-Nemo-Minitron-128K-Instruct, которая генерирует динамичный, контекстно актуальный ответ. Если требуется дополнительный контекст, можно использовать подход генерации с дополнением извлечения (RAG), где модель встраивания, такая как E5-Large-Unsupervised, преобразует текст в векторные представления. Эти векторы затем используются в поиске по сходству для извлечения соответствующих знаний, обогащая ответ SLM дополнительным контекстом.
- Дайте персонажам голос с помощью TTS: Сгенерированный ответ синтезируется в живые голоса, обеспечивая естественную интонацию и выразительность.
- Создайте интерактивную анимацию: Затем произнесенный ответ управляет лицевыми формами для анимации в реальном времени с помощью Audio2Face-3D, обеспечивая точную синхронизацию губ и выразительные движения персонажа.
На протяжении всего этого процесса регистрация GPU и CIG обеспечивают выполнение рабочих нагрузок ИИ наряду с графическими задачами при минимальном влиянии на частоту кадров. Это гарантирует бесшовный опыт в реальном времени.
Для получения дополнительной информации об использовании этих плагинов и моделей для выполнения в процессе выполнения, смотрите следующие разделы.
Начало работы с инференсом ACE на устройстве
В этом разделе описывается, как использовать NVIGI с SLM ACE, чтобы включить инференс ИИ в процессе выполнения наряду с вашими рабочими нагрузками рендеринга.
NVIGI включает пакетные файлы, которые загружают модели из репозиториев, таких как NVIDIA NGC и Huggingface. Это минимизирует начальную загрузку и гарантирует, что вам нужно будет загрузить только те модели, с которыми вы хотите работать. Также он включает набор плагинов локального инференса, которые мы выделим позже, чтобы помочь вам начать.
Инициализация NVIGI
Первый шаг — инициализировать фреймворк NVIGI. Этот процесс настраивает пути к плагинам, ведение журнала и основные конфигурации, необходимые для функционирования NVIGI в вашей игре.
Следующий кодовый пример показывает, как инициализировать NVIGI в вашей игре:
nvigi::Preferences preferences{};
preferences.logLevel = nvigi::LogLevel::eVerbose; // Включить подробное ведение журнала
preferences.utf8PathsToPlugins = {"path/to/plugins"}; // Установить путь к плагину
preferences.utf8PathToLogsAndData = "path/to/logs"; // Определить путь к журналу
if (nvigiInit(preferences, nullptr, nvigi::kSDKVersion) != nvigi::kResultOk) {
std::cerr << "Не удалось инициализировать NVIGI." << std::endl;
}
Загрузка плагинов и модели
Архитектура NVIGI основана на системе плагинов, которая предлагает модульность и гибкость. Плагины включены для классов моделей ИИ, таких как LLMs, ASR и извлечение встраиваний. Эти плагины позволяют развертывать модели ИИ из диапазона ACE для реализации необходимых функций и поведения.
Каждый плагин разработан для поддержки нескольких моделей, которые используют определенный интерфейс и основное API. NVIGI включает плагины в процессе выполнения с поддержкой популярных бэкендов, таких как GGML (llama.cpp, whisper.cpp, embedding.cpp), ONNX Runtime и DirectML.
Вот некоторые примеры:
nvigi.plugin.asr.ggml.cuda: Преобразует речь в текст с использованием GGML и CUDA.nvigi.plugin.gpt.ggml.cuda: Обеспечивает диалоги и размышления, сгенерированные ИИ.nvigi.plugin.embed.ggml.*: Находит соответствующий текст на основе настроения для обеспечения лучшего контекста.
Чтобы использовать плагин GPT, сначала загрузите его интерфейс для запроса возможностей модели:
// Загрузите интерфейс плагина GPT nvigi::IGeneralPurposeTransformer* gpt = nullptr; nvigiGetInterfaceDynamic(nvigi::plugin::gpt::ggml::cuda::kId, &gpt, ptr_nvigiLoadInterface);
NVIGI поставляется с предустановленным набором моделей, которые можно загрузить вручную, чтобы начать, но вы можете получить более модели GGUF как из NGC, так и на Huggingface. Затем вы определяете параметры модели для плагина, такие как следующий пример:
// Настройка параметров модели
nvigi::CommonCreationParameters common{};
common.utf8PathToModels = "path/to/models";
common.numThreads = 8; // Количество потоков ЦП
common.vramBudgetMB = vram; // Выделение видеопамяти в МБ
common.modelGUID = "{YOUR_MODEL_GUID}"; // GUID модели
Когда интерфейс и параметры модели загружены, настройте экземпляр или инференс в процессе выполнения:
// Создайте экземпляр GPT
nvigi::InferenceInstance* gptInstance = nullptr;
if (gpt->createInstance(common, &gptInstance) != nvigi::kResultOk || !gptInstance) {
std::cerr << "Не удалось создать экземпляр GPT." << std::endl;
}
// Используйте экземпляр GPT для инференса
Создание конфигурации времени выполнения и инференса
Интерфейс InferenceInstance предоставляет API для выполнения задач инференса и настраивается с помощью InferenceExecutionContext. Этот интерфейс позволяет настроить входные слоты, параметры времени выполнения и механизмы обратного вызова для получения ответов модели.
Задачи инференса полагаются на входные данные, такие как текст или аудио игрока, в сочетании с конфигурациями времени выполнения. Контекст для определения личности и роли игрового персонажа может быть установлен с использованием слота nvigi::kGPTDataSlotSystem:
// Определите роль NPC в системном запросе
std::string npcPrompt = "Вы полезный NPC по имени TJ в фэнтезийной игре.";
nvigi::CpuData systemPromptData(npcPrompt.length() + 1, npcPrompt.c_str());
nvigi::InferenceDataText systemPromptSlot(systemPromptData);
// Установите параметры времени выполнения
nvigi::GPTRuntimeParameters runtime{};
runtime.tokensToPredict = 200; // Ограничьте предсказание токенов до 200 токенов
runtime.interactive = true; // Включите многоходовые разговоры
std::vector<nvigi::InferenceDataSlot> slots = {
{nvigi::kGPTDataSlotSystem, &systemPromptSlot}
};
// Контекст инференса
nvigi::InferenceExecutionContext gptExecCtx{};
gptExecCtx.instance = gptInstance;
gptExecCtx.runtimeParameters = runtime;
gptExecCtx.inputs = slots.data();
Динамическое взаимодействие между игроком и игровым персонажем может управляться следующим образом:
std::string userInput = "Как вас зовут?"; // пример ввода пользователя
nvigi::CpuData userInputData(userInput.length() + 1, userInput.c_str());
nvigi::InferenceDataText userInputSlot(userInputData);
slots = {{nvigi::kGPTDataSlotUser, &userInputSlot}};
gptExecCtx.inputs = slots.data();
Запустите инференс и обработку ответа асинхронно:
if (gptExecCtx.instance->evaluate(&gptExecCtx) == nvigi::kResultOk) {
std::cout << "Инференс успешно завершен!" << std::endl;
}
Каждый ход диалога обрабатывается через входной слот nvigi::kGPTDataSlotUser, сохраняя контекст для многоходового диалога.
Вы также можете реализовать функцию обратного вызова, чтобы захватить ответ персонажа для отображения в игре, пример которой показан в следующем разделе.
Включите управление GPU и интеграцию рендеринга
Рабочие нагрузки ИИ в играх выполняются параллельно с графическими задачами, поэтому эффективное управление GPU имеет решающее значение для поддержания частоты кадров. NVIGI использует CIG для эффективного планирования рабочих нагрузок GPU.
Для эффективного планирования графических и вычислительных задач NVIGI должен получить прямую очередь D3D, которую использует ваша игра для графики. Структура D3D12Parameters обеспечивает прямую интеграцию NVIGI с графической цепочкой рендеринга, позволяя выполнять задачи ИИ параллельно без влияния на графическую производительность.
Следующий код показывает, как включить CIG для инференса ИИ с помощью интерфейса NVIGI IHWICuda, используя плагин ASR в качестве примера:
// Включите вычисления в графике (CIG)
nvigi::IHWICuda* icig = nullptr;
if (nvigiGetInterface(nvigi::plugin::hwi::cuda::kId, &icig) != nvigi::kResultOk || !icig) {
std::cerr << "Не удалось загрузить интерфейс CIG." << std::endl;
return;
}
// Настройте параметры D3D12
nvigi::D3D12Parameters d3d12Params{};
d3d12Params.device = myD3D12Device; // Устройство D3D12, используемое для рендеринга
d3d12Params.queue = myD3D12CommandQueue; // Очередь команд графики
// Активируйте управление GPU как для инференса, так и для рендеринга
if (icig->enableComputeInGraphics(d3d12Params) != nvigi::kResultOk) {
std::cerr << "Не удалось включить вычисления в графике." << std::endl;
return;
}
std::cout << "Вычисления в графике успешно включены." << std::endl;
Для настройки управления GPU NVIGI в Unreal Engine 5 (UE5) используйте глобальный динамический интерфейс рендеринга (RHI), чтобы получить доступ к устройству D3D вашей игры и очереди команд.
Конфигурация CIG в UE5 проста:
// Код, специфичный для UE5, для получения ресурсов D3D12
#include "ID3D12DynamicRHI.h"
ID3D12DynamicRHI* RHI = nullptr;
if (GDynamicRHI && GDynamicRHI->GetInterfaceType() == ERHIInterfaceType::D3D12)
{
RHI = static_cast<ID3D12DynamicRHI*>(GDynamicRHI);
}
ID3D12CommandQueue* CmdQ = nullptr;
ID3D12Device* D3D12Device = nullptr;
if (RHI) {
CmdQ = RHI->RHIGetCommandQueue(); // Получите очередь команд графики
int DeviceIndex = 0;
D3D12Device = RHI->RHIGetDevice(DeviceIndex); // Получите устройство D3D12
}
// Настройте параметры D3D12 для IGI
nvigi::D3D12Parameters d3d12Params{};
d3d12Params.device = D3D12Device;
d3d12Params.queue = CmdQ;
// Передайте параметры в экземпляры IGI
nvigi::CommonCreationParameters commonParams{};
commonParams.chain(d3d12Params);
// Пример: создание экземпляра ASR с CIG
nvigi::ASRCreationParameters asrParams{};
asrParams.common = &commonParams;
nvigi::InferenceInstance* asrInstance = nullptr;
iasr->createInstance(asrParams, &asrInstance);
Запустите инференс
Задачи инференса в NVIGI включают в себя настройку контекста беседы, обработку вводов пользователя и динамическую генерацию ответов. Следующие шаги описывают, как эффективно выполнять задачи инференса в вашей игровой среде.
Для выполнения инференса необходимо создать контекст инференса, который включает в себя следующее:
- Входные слоты: Подготовьте входные данные (текст пользователя, голосовые данные) в формате, который модель может обработать.
- Параметры времени выполнения: Определите поведение инференса, такие как количество предсказанных токенов или параметры интерактивности.
- Механизмы обратного вызова: Укажите, как обрабатывать выходные результаты.
Контекст инференса определяет, как обрабатываются входные и выходные данные. Начните с включения интерактивного режима и подготовки параметров времени выполнения:
// Настройка параметров времени выполнения для GPT
nvigi::GPTRuntimeParameters runtime{};
runtime.tokensToPredict = 200; // Предсказание до 200 токенов
runtime.interactive = true; // Включите интерактивный режим
// Настройте контекст инференса
nvigi::InferenceExecutionContext gptExecCtx{};
gptExecCtx.instance = gptInstance; // Используйте экземпляр GPT, созданный ранее
gptExecCtx.runtimeParameters = runtime;
gptExecCtx.callback = [](const nvigi::InferenceExecutionContext* execCtx, nvigi::InferenceExecutionState state, void* userData) {
if (state == nvigi::kInferenceExecutionStateDone && execCtx->outputs){
const nvigi::InferenceDataText* responseText = nullptr;
execCtx->outputs->findAndValidateSlot(nvigi::kGPTDataSlotResponse, &responseText);
if (responseText) {
std::cout << "Ответ NPC: " << responseText->getUtf8Text() << std::endl;
}
}
return state;
};
Вы можете начать разговор, предоставив системный запрос, который определяет личность или роль NPC. Используйте слот nvigi::kGPTDataSlotSystem для этой цели:
// Настройка контекста беседы
std::string npcPrompt = "Вы полезный NPC в фэнтезийной игре. Ответьте обдуманно на вопросы игрока.";
nvigi::CpuData systemPromptData(npcPrompt.length() + 1, npcPrompt.c_str());
nvigi::InferenceDataText systemPromptSlot(systemPromptData);
std::vector<nvigi::InferenceDataSlot> slots = {
{nvigi::kGPTDataSlotSystem, &systemPromptSlot} // Установите системный запрос
};
gptExecCtx.inputs = slots.data();
gptExecCtx.numInputs = slots.size();
// Выполните инициализацию контекста беседы
if (gptExecCtx.instance->evaluate(&gptExecCtx) != nvigi::kResultOk) {
std::cerr << "Не удалось инициализировать контекст беседы." << std::endl;
return;
}
Список доступных плагинов NVIGI
Вы можете начать создавать агентные структуры для инференса на устройстве с помощью следующих моделей речи и интеллекта уже сегодня.
| Плагин NVIGI | Поддерживаемое оборудование для инференса | Поддерживаемые модели |
| Речь – ASR Локальный GGML | GPU или ЦП с поддержкой CUDA | Whisper ASR |
| Речь – ASR Локальный TRT | GPU с поддержкой CUDA | NVIDIA RIVA ASR (скоро) |
| Язык – GPT Локальный ONNX DML | GPU или ЦП с поддержкой ONNX | Mistral-7B-Instruct |
| Язык – GPT Локальный GGML | GPU или ЦП с поддержкой CUDA |
Llama-3.2-3b Instruct Nemotron-Mini-4B-Instruct Mistral-Nemo-Minitron-2B-128k-Instruct Mistral-Nemo-Minitron-4B-128k-Instruct Mistral-Nemo-Minitron-8B-128k-Instruct Nemovision-4B-Instruct |
| RAG – Встраивание Локальный GGML | GPU или ЦП с поддержкой CUDA | E5 Large Unsupervised |
Заключение
NVIDIA ACE и NVIGI представляют собой следующий шаг в развитии разработки игр на основе ИИ. Сочетая передовые модели генеративного ИИ ACE с бесшовной интеграцией и оптимизированной производительностью NVIGI, вы можете разблокировать новые уровни интерактивности и погружения.
От динамичных диалогов NPC и распознавания речи в реальном времени до реалистичных анимаций и контекстной памяти, ACE и NVIGI предлагают выгодное и масштабируемое решение для создания интеллигентных, автономных персонажей.
Начните работу с NVIDIA ACE с NVIGI уже сегодня.
