Точность цитат имеет большое значение для поддержания целостности как академического, так и сгенерированного ИИ контента. Когда цитаты неточные или неверные, они могут вводить читателей в заблуждение и распространять ложную информацию. Мы — группа исследователей из Университета Сиднея, специализирующаяся на машинном обучении и ИИ, разрабатываем инструмент на базе ИИ, способный эффективно проверять и анализировать семантическую точность цитат.
Указание на источник для фактических утверждений может помочь читателям доверять его достоверности, укрепить авторитет автора и способствовать прозрачности, показывая источник информации. Однако обеспечение семантической точности цитат — это трудоемкий процесс, который часто требует глубокого понимания темы.
Наш собственный опыт столкновения с разочарованиями и проблемами, вызванными неточными цитатами, побудил нас разработать надежное и масштабируемое решение — инструмент проверки семантической цитаты. Это решение упрощает процесс проверки цитат и улучшает целостность исследований в различных областях.
Необходимость в проверке цитат стала более актуальной с растущим использованием моделей с большим языком (LLM). Недавние достижения в методах усиленной генерации (RAG) помогают снизить количество галлюцинаций в сгенерированном контенте. Тем не менее, остаются значительные проблемы с установлением надежности без дополнительных методов проверки.
Мы столкнулись с этой проблемой, разрабатывая Приложение для оценки влияния исследований, которое генерирует индивидуальные отчеты о влиянии для научных работ в области медицины и здравоохранения. Несмотря на свою мощь, приложение в настоящее время не может самостоятельно проверять утверждения в цитатах или проверять их соответствие заявлениям в оригинальных источниках.
В этом посте представлен инструмент проверки семантической цитаты, который направлен на ускорение процессов валидации, поддержание высокой точности и предоставление релевантных контекстуальных фрагментов для более глубокого понимания цитируемых материалов. Этот инструмент автоматизирует проверку цитат, сопоставляя фактические утверждения с ссылочными текстами. Он разработан с использованием микросервисов NVIDIA NIM с дополнительной поддержкой основных поставщиков API LLM, сочетая индивидуальную модель, настроенную на ссылочных данных, с гибкими вариантами развертывания.
 Техническая реализация и интеграция с NVIDIA
Техническая реализация и интеграция с NVIDIA
Инструмент проверки семантической цитаты появился на Generative AI CodeFest Australia в декабре 2024 года, мероприятии, сосредоточенном на практической разработке инструментов ИИ и повышении квалификации. Стратегия реализации ориентировалась на разработку приложения на базе микросервисов, использующего экосистему NVIDIA NIM, в частности, с использованием NVIDIA NeMo Retriever для задач внедрения и извлечения, в дополнение к уточненным языковым моделям для семантического анализа и проверки. NeMo Retriever — это коллекция микросервисов, предоставляющих информацию, доступ к которой соответствует мировым стандартам с высокой точностью и максимальной конфиденциальностью данных.
Ключевые компоненты NVIDIA включают:
- Расширенные встраивания и повторная ранжировка: Специализированные сервисы NVIDIA трансформируют текст в высокоразмерные встраивания и ранжируют отрывки на основе релевантности утверждений, значительно снижая количество ложноположительных результатов в фильтрации контента благодаря оптимизированному семантическому соответствию.
- Проверка с поддержкой LLM: Используя NVIDIA NIM для LLM, система выполняет глубокий семантический анализ ранжированных отрывков, предоставляя детализированные обоснования для проверок, которые соответствуют экспертному суждению.
- Настройка модели: Чтобы оптимизировать точность и скорость обработки, мы адаптировали модели LLama 3.1 (варианты 8B и 70B) с использованием индивидуального набора данных утверждений цитат, ссылок и результатов проверки. Набор данных был основан на наиболее цитируемых публикациях 2024 года в самых разных областях исследований, включая медицину, физику, математику, информатику, геологию и экологическую науку. Утверждения цитат и ссылки (с 2023 года и далее) были извлечены и аннотированы. Мы также увеличили набор данных с помощью синтетических утверждений и аннотаций, созданных с использованием GPT-4o. Для обучения модели мы использовали восемь GPU NVIDIA A100 Tensor Core с общей памятью 640 ГБ (предоставленной NVIDIA в рамках Generative AI CodeFest Australia).
Архитектура пайплайна
Инструмент проверки семантической цитаты работает через пять упрощенных этапов:
- Обработка входных данных: Обрабатывает цитатные утверждения и отссылочные документы через надежную систему приема с встроенной проверкой формата и обработкой ошибок. Загрузчик документов поддерживает текстовые файлы, .pdf и .docx.
- Обработка документа: Выполняет проверку формата, парсинг и стратегическое деление, одновременно генерируя оптимизированные встраивания для семантического соответствия. Также обрабатывает текст цитаты в структурированные утверждения с использованием LLM.
- Управление векторами: Реализует архитектуру с двойным кэшированием для хранения документов и векторов, что позволяет ускорить извлечение и уменьшить затраты на обработку.
- Сопоставление и анализ: Совмещает сопоставление по сходству, повторную ранжировку и анализ LLM в многослойном подходе для всесторонней проверки.
- Генерация выходных данных: Создает классификацию поддержки, причин для проверки, релевантные фрагменты и коэффициенты доверия.
Обработка пайплайна использует LangChain и ChromaDB для реализации RAG и может взаимодействовать с языковыми моделями и моделями встраивания OpenAI и NVIDIA. Рисунок 2 предоставляет обзор процесса пайплайна для инструмента проверки семантической цитаты.

Обзор веб-приложения и ключевые функциональности
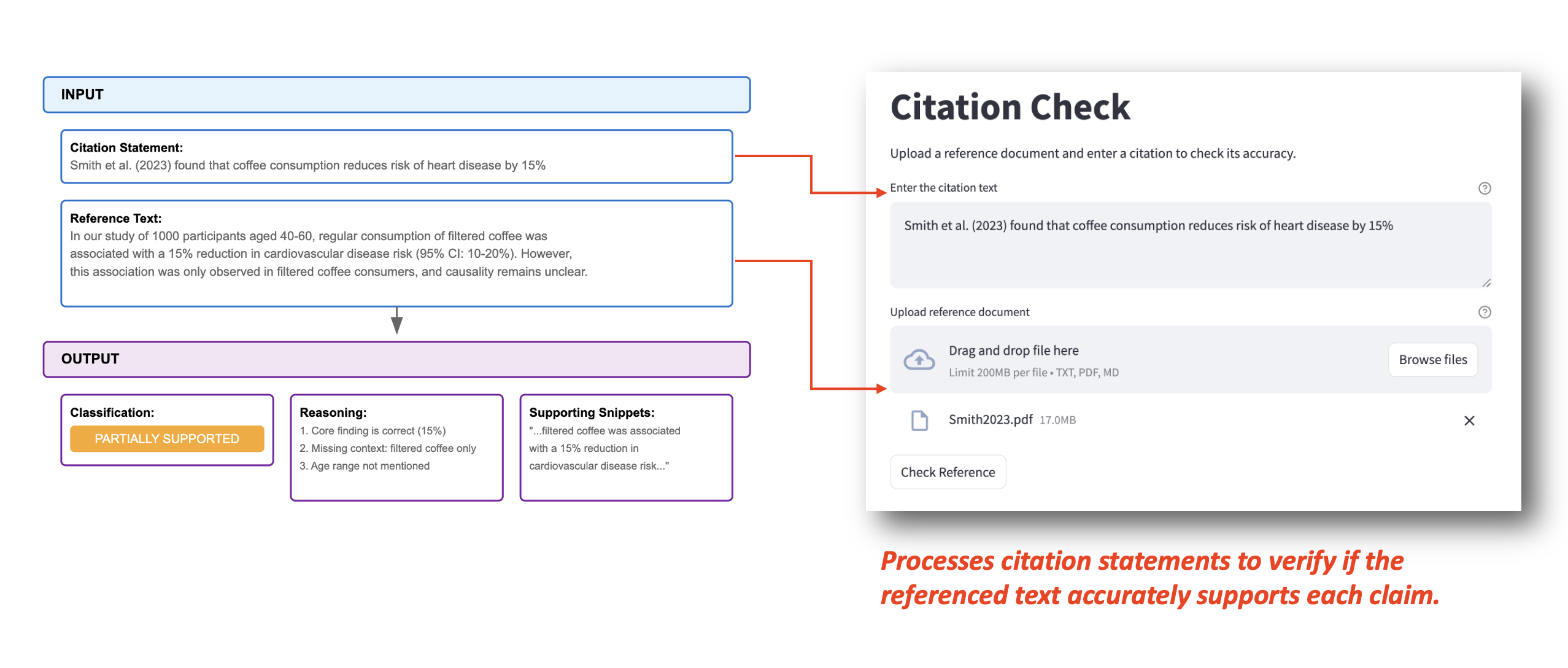
В качестве исходного прототипа мы разработали интуитивно понятный веб-интерфейс с использованием Streamlit, чтобы сделать инструмент проверки цитат легко доступным и упростить рабочий процесс автоматизированной проверки цитат.
Пользователи могут вводить цитатные утверждения и файл со ссылкой напрямую, как показано в примере ниже. Система обрабатывает эту информацию и генерирует три ключевых вывода:
- Классификация (в этом случае показано как ЧАСТИЧНО ПОДДЕРЖИВАЕМАЯ)
- Подробное обоснование классификации (перечисление трех конкретных моментов о ключевом выводе, отсутствующем контексте и возрастной группе в этом случае)
- Релевантные вспомогательные фрагменты из исходного текста
Использование микросервисов NVIDIA для реализации LLM, извлечения документов и ранжирования
Интерфейс конфигурации демонстрирует ключевые интеграции NVIDIA через гибкий выбор поставщиков LLM, оптимизированные услуги встраивания и мощные механизмы извлечения с использованием хранилища векторов Chroma и FlashrankRerank. Локальная конфигурация конечной точки обеспечивает безопасную обработку конфиденциальных данных, сохраняя производительность.

Классификации точности
Инструмент валидации предоставляет детальную оценку цитат через четыре отдельные категории:
- Поддерживается: Полное соответствие и правильный контекст
- Частично поддерживается: Основные утверждения поддерживаются, но отсутствует контекст или нюансы
- Не поддерживается: Утверждения противоречат источнику или отсутствуют
- Неопределенно: Случаи с неоднозначной или недостаточной информацией
Схема классификации разработана для того, чтобы сбалансировать детализированность и простоту, обеспечивая соответствие потенциальным действиям для исследователей и рецензентов. Поддерживаемые цитаты не требуют изменений, частично поддерживаемым может потребоваться небольшая корректировка, неподдерживаемые цитаты требуют серьезных правок или удаления, а неопределенные случаи требуют дополнительной проверки.

Обоснование и поддерживающие доказательства
Инструмент также предоставляет детализированные обоснования своей классификации, анализируя конкретные пробелы между цитатой и исходным текстом, такие как недостающие детали, методологические нюансы, контекстные упущения или потенциальные искажения полученных выводов. Поддерживающие доказательства представляются через соответствующие текстовые фрагменты из ссылочного документа, с указанием оценок релевантности, позволяя пользователям напрямую проверить процесс принятия решений инструмента.

Заключение
Инструмент проверки семантической цитаты автоматизирует проверку цитат, сравнивая фактические утверждения с ссылочными текстами. Разработанный с использованием микросервисов NVIDIA NIM с дополнительной поддержкой основных поставщиков API LLM, он сочетает индивидуальную модель, настроенную на ссылочных данных, с гибкими вариантами развертывания. Инструмент выполняет семантическую проверку утверждений и извлекает поддерживающие доказательства, классифицируя цитаты на четыре категории: Поддерживается, Частично поддерживается, Не поддерживается и Неопределенно. Инструмент может быть легко развернут в качестве веб-приложения, что позволяет систематически проверять цитаты, сокращая время проверки с часов до секунд, при этом повышая точность и качество исследований.
В будущем мы планируем оптимизировать процесс проверки цитат. Мы внедрим автоматическое извлечение цитат и ссылок из любых документов, а также полное извлечение текста открытых ссылок. Это улучшение исключит требования к ручному вводу, значительно сократив время проверки как для традиционного академического контента, так и для сгенерированных ИИ произведений. Это позволит осуществить прямое извлечение и проверку источников, интегрировавшись с академическими базами данных и серверами препринтов.
Дальнейшая разработка включает возможности пакетной обработки для одновременной обработки нескольких цитат, что будет полезно для редактирования рукописей, систематических обзоров и быстрой проверки сгенерированного ИИ контента. Эти улучшения превратят инструмент в комплексное решение для обеспечения целостности цитат, поддерживая исследователей, редакционные группы и создателей контента в соблюдении высоких стандартов точности как для работ, написанных людьми, так и для произведений, сгенерированных ИИ. Для получения дополнительной информации и обновлений посетите RefCheckAI.
Изучите NVIDIA NIM, чтобы ускорить разработку своего ИИ и решить реальные проблемы. Узнайте больше о NIM и его возможностях для создания инновационных решений, таких как этот инструмент проверки цитат.
Благодарности
Эта работа была выполнена частично на Generative AI Codefest в Австралии, часть программы Open Hackathons. Мы хотели бы поблагодарить OpenACC-Standard.org за их поддержку. Мы благодарим Департамент промышленности, науки и ресурсов правительства Австралии через Национальный центр ИИ и Национальную вычислительную инфраструктуру (NCI) за организацию Generative AI CodeFest Australia вместе с NVIDIA и Sustainable Metal Cloud (SMC). Проект поддерживается Сиднейским хабом информатики (SIH) Университета Сиднея.
