По мере роста объемов данных в предприятиях различных отраслей, Apache Parquet стал популярным форматом для их хранения. Apache Parquet — это колонный формат хранения, разработанный для эффективной обработки данных в больших масштабах. Организуя данные по столбцам, а не по строкам, Parquet позволяет выполнять высокопроизводительные запросы и анализ, поскольку он может читать только необходимые столбцы для запроса, избегая полного сканирования строк. Эффективная структура данных Parquet сделала его популярным выбором в современной аналитической экосистеме, особенно для задач, связанных с Apache Spark.
Ускоритель RAPIDS для Apache Spark, построенный на cuDF, поддерживает Parquet как формат данных для чтения и записи с ускорением на графических процессорах (GPU). Для многих крупных задач Spark, где размеры входных данных исчисляются терабайтами, эффективные сканирования Parquet критически важны для достижения хорошей производительности во время выполнения.
В этом посте мы обсудим, как смягчить ограничения по занятости, вызванные использованием большего количества регистров, и поделимся результатами бенчмарков.
Формат данных Apache Parquet
Формат файлов Parquet позволяет хранить данные в колонном формате с использованием колонок, собранных в группы строк. Метаданные отделены от самих данных, что позволяет при необходимости разбивать столбцы на несколько файлов (Рисунок 1).
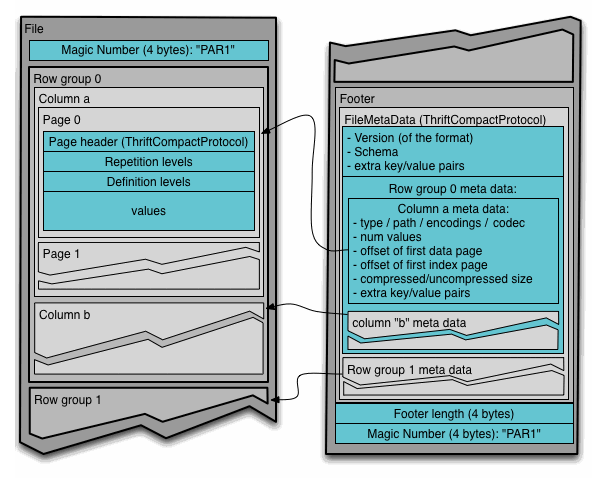
Формат Parquet поддерживает различные типы данных. Метаданные определяют, как эти типы должны интерпретироваться, что позволяет им представлять более сложные логические типы, такие как временные метки, строки, десятичные дроби и так далее.
Также можно использовать метаданные для указания более сложных структур, таких как вложенные типы и списки. Данные могут быть представлены в различных форматах, таких как простые значения, словари, кодирование длины пробега, упаковка битов и многое другое.
- BOOLEAN: 1 битовый булев тип - INT32: 32-битные целые числа со знаком - INT64: 64-битные целые числа со знаком - INT96: 96-битные целые числа со знаком - FLOAT: 32-битные значения с плавающей запятой IEEE - DOUBLE: 64-битные значения с плавающей запятой IEEE - BYTE_ARRAY: массивы байтов произвольной длины - FIXED_LEN_BYTE_ARRAY: массивы байтов фиксированной длины
Ограничения по занятости Parquet на GPU
До появления ускорителя RAPIDS для Apache Spark предыдущая реализация сканирования Parquet была монолитным ядром cuDF, которое поддерживало все типы столбцов Parquet в одном наборе кода обработки.
С увеличением использования Spark на GPU для клиентов с данными Parquet, было вложено больше времени в понимание характеристик производительности сканирования Parquet, поскольку это представляло собой критически важный компонент производительности. Существует несколько общих ресурсов, которые влияют на то, насколько эффективно может работать ядро:
- Потоковые микропроцессоры (SMs): Основное вычислительное устройство GPU, отвечающее за выполнение вычислительных задач.
- Общая память: Внутренняя память GPU, выделенная для каждого блока потоков, чтобы все потоки в одном блоке могли получать доступ к одной и той же общей памяти.
- Регистры: Быстрая встроенная память GPU, которая хранит информацию, используемую одним потоком для вычислительных операций, выполняемых SM.
Анализируя сканирования Parquet, мы заметили, что общая занятость GPU была ниже желаемого из-за достижения пределов регистров. Использование регистров определяется тем, как компилятор CUDA генерирует код в зависимости от логики ядра и управления данными.
Для монолитного ядра Parquet сложность поддержки всех типов столбцов создавала большое и сложное ядро с высоким использованием общей памяти и регистров. Хотя одно монолитное ядро может объединять код, его сложность ограничивала возможные виды оптимизаций и приводила к ограничениям производительности в масштабе.
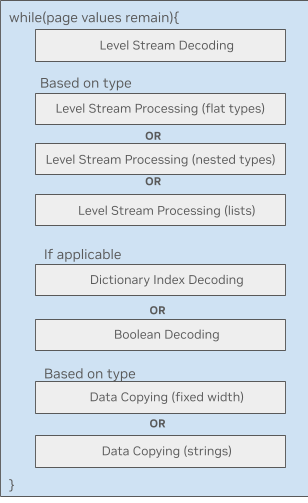
Рисунок 2 иллюстрирует цикл обработки данных Parquet на GPU. Каждый из блоков представляет собой значительное и сложное количество кода ядра, которое может иметь свои собственные требования к общей памяти. Многие из блоков зависят от типа, что приводит к раздуванию ядра, загружаемого в память.
В частности, одним из ограничений было то, как блоки Parquet декодировались внутри групп. Существовала последовательная зависимость, из-за которой группы должны были ждать завершения ранее упорядоченных групп, прежде чем обрабатывать свои блоки данных. Это позволяло различным частям процесса декодирования происходить в разных группах, но создавало неэффективную зависимость для выполнения работы на GPU.
Переход к алгоритму декодирования на уровне блока был критически важен для производительности, но увеличивал бы количество регистров и еще больше ограничивал занимательность из-за сложности добавленного обмена данными и синхронизации.
Микроядра Parquet в cuDF
Чтобы смягчить ограничения по занятости, вызванные большим использованием регистров, мы попробовали идею более мелкого ядра для предварительной обработки данных типа списков в Parquet. Мы выделили часть кода из монолитного ядра в самостоятельное ядро, и результаты были впечатляющими. Общие бенчмарки показали более быстрые времена выполнения, а трассировки GPU продемонстрировали улучшенную занятость.
После этого мы попробовали тот же подход для различных типов столбцов. Микроядра для различных типов использовали шаблоны C++ для повторного использования возможностей. Это упростило код для обслуживания и отладки для каждого типа.

Подход микроядра Parquet использует оптимизацию времени компиляции, чтобы проходить только через необходимые пути кода для обработки данного типа. Вместо одного монолитного ядра, содержащего все возможные пути кода, можно генерировать множество отдельных микроядров, которые содержат только код, необходимый для этого пути.
Это можно сделать с помощью if constexpr на этапе компиляции, чтобы код выглядел обычно, но не содержал никаких путей кода, которые никогда не будут использованы для конкретной комбинации атрибутов данных (строки или фиксированная ширина, списки или без списков и так далее).
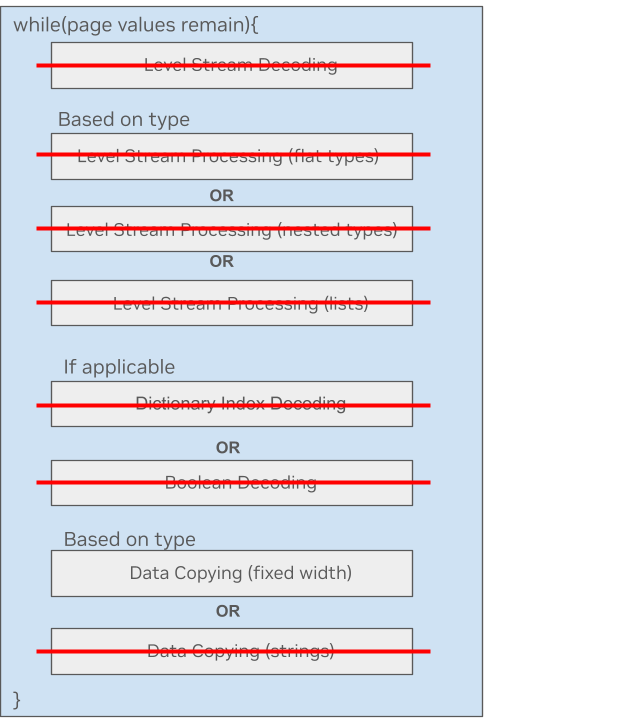
Вот простой пример для обработки столбцов фиксированной ширины. Вы можете увидеть, что большая часть обработки не нужна и пропускается в новом подходе микроядра. Только копирование данных необходимо для этого типа.
Чтобы решить проблему узких мест между группами, новые микроядра позволили обрабатывать целые блоки на каждом этапе, чтобы группы могли независимо обрабатывать данные более эффективно. Это было особенно значимо для строк, чтобы обеспечить полные блоки из 128 потоков на GPU для копирования строк, тогда как предыдущая реализация использовала только одну группу для копирования строк.
Мы провели локальные бенчмарки с использованием графического процессора NVIDIA RTX A5000 24 ГБ с предварительно загруженными сжатыми данными Parquet Snappy объемом 512 МБ в устройствах буферов. Для тестирования чанков чтения мы читали по 500 КБ за раз. Тестовые данные включали несколько вариантов:
- Кардинальность 0 и 1000
- Длина пробега 1 и 32
- 1% нулей
- Адаптивное использование словаря, если данные повторялись
Рисунок 5 показывает результаты в терминах улучшения пропускной способности для типов столбцов Parquet с новым подходом микроядер на GPU.

Оптимизация чтения чанков столбцов списков также увеличила пропускную способность на 117% для чтения 500 КБ.
Начало работы с Apache Spark на GPU
Parquet является ключевым форматом данных, широко используемым для обработки больших данных. GPU может ускорить сканирование данных Parquet в Apache Spark с помощью оптимизированных микроядер в cuDF.
Предприятия могут воспользоваться ускорителем RAPIDS для Apache Spark, чтобы без проблем перенести рабочие нагрузки Apache Spark на графические процессоры NVIDIA. Ускоритель RAPIDS для Apache Spark использует графические процессоры для ускорения обработки, объединяя мощь библиотеки RAPIDS cuDF и масштаб Spark распределённой вычислительной платформы. Запускайте существующие приложения Apache Spark на графических процессорах без изменений в коде, просто запустив Spark с помощью JAR-файла плагина RAPIDS Accelerator для Apache Spark.
Получите практический опыт работы с обработкой сканирований Parquet и ускорителем RAPIDS для Apache Spark, используя ноутбук Colab по ускорению Parquet Spark RAPIDS.